
近期,北京通用人工智能研究院通用视觉实验室(bigai.ai/department/)联合北京大学人工智能研究院朱毅鑫团队在计算机视觉顶级会议CVPR 2023上发表了题为 Diffusion-based Generation, Optimization, and Planning in 3D Scenes 的论文。
本文提出了一个名为SceneDiffuser的条件生成模型。SceneDiffuser 基于扩散模型,能够在三维场景中实现场景感知式生成、基于物理的优化和目标导向的规划。
SceneDiffuser为三维场景中的生成、优化和规划提供了一个统一的框架。SceneDiffuser 可以应用于广泛的三维场景理解任务,如三维场景中的人体姿态或运动生成,物体级灵巧手抓握生成,室内导航路径规划,以及桌面环境下的机械臂运动规划。大量的实验结果表明,SceneDiffuser 相比以往的方法实现了性能大幅提升,展示了在三维场景理解领域的巨大潜力。

论文作者:黄思远、王赞(共同一作)、李浦豪、贾宝雄、刘腾宇、朱毅鑫、梁玮、朱松纯项目链接:https://scenediffuser.github.io/
一、论文概述

图1:SceneDiffuser 适用于广泛的三维场景理解任务,如人体姿态生成,人体运动生成,灵巧手抓握生成,室内导航路径规划,以及机械臂运动规划。
长期以来,计算机视觉、图形学和机器人等领域一直追求一个共同的目标:让模型具备在三维场景中生成、优化和规划的能力。然而,现有的模型在应对广泛的三维场景理解任务时,面临两个根本限制。
首先,针对三维场景约束下的条件生成任务,以往的方法通常使用易学、易采样的条件变分自编码器(cVAE)学习相应的后验分布 [1,2,3]。然而,后验坍塌的问题会限制最终生成结果的多样性,尤其在三维场景复杂多样时问题更加显著。其次,单独地优化或规划会导致不合理的结果 [4,5,6],同时使模型缺乏长期规划和轨迹调整的能力,限制了模型在新场景中的泛化表现。虽然三维场景中的生成、优化和规划存在密切关系,但目前缺乏一个统一的框架来解决不同模型之间的差异。
为了克服这些问题,本文提出了一个名为 SceneDiffuser 的条件生成模型。SceneDiffuser 基于扩散模型 [7,8],能够在三维场景中实现场景感知式生成、基于物理的优化和目标导向的规划。SceneDiffuser 消除了上述三个方面的差异,为三维场景中的生成、优化和规划提供了一个统一的框架。SceneDiffuser 可以应用于广泛的三维场景理解任务,如三维场景中的人体姿态或运动生成,物体级灵巧手抓握生成,室内导航路径规划,以及桌面环境下的机械臂运动规划。大量的实验结果表明,SceneDiffuser 相比以往的方法实现了性能大幅提升,展示了在三维场景理解领域的巨大潜力。
二、SceneDiffuser模型介绍
在训练过程中,SceneDiffuser 结合去噪过程学习了一个基于扩散模型的场景条件生成模型。在推断过程中,通过统一的迭代式引导采样(guided-sampling)框架,将优化问题或规划问题的目标函数注入到扩散模型的逆向过程中,使得 SceneDiffuser 能够同时解决了场景感知式生成、基于物理的优化和目标导向的规划。SceneDiffuser 具备以下三个优势:
1. 生成:在扩散模型的基础上,SceneDiffuser 解决了场景条件生成模型中的后验坍塌问题。
2. 优化:SceneDiffuser 将基于物理的目标函数注入到每个采样步骤中作为条件引导,从而可以在学习和采样过程中实现物理合理的生成。
3. 规划:SceneDiffuser 拥有一个物理和目标感知的轨迹规划器,能够避开场景中的障碍物和死角,可以更好地泛化到长期规划和新的三维场景。图 2 阐释了 SceneDiffuser 核心的优化/规划引导的采样过程。

图2: SceneDiffuser 优化/规划引导的采样过程。
图 3 展示了 SceneDiffuser 的一个完整的去噪过程(以人体姿态生成为例)。在基于物理的目标函数的约束下,SceneDiffuser 能够从高斯噪声中还原出在三维场景中合理且真实的人体姿态。

图3: 完整的去噪过程。
图 4 介绍了 SceneDiffuser 完整的采样算法。

图4: SceneDiffuser 的采样算法
本文最终在五个场景理解任务上来评估 SceneDiffuser,包括三维场景中的人体姿态和运动生成,灵巧手抓握生成,室内导航路径规划,以及机械臂运动规划。
相比于传统的 cVAE 方法 [1],通过使用 SceneDiffuser 进行三维场景中的人体姿态生成,可以获得更加合理的人体姿态,同时保留相当水平的多样性,可视化结果如图 5 所示。此外,通过优化引导的采样策略,SceneDiffuser 极大地提高了生成结果的合理性,这表明所提出的方法在具有基于物理约束的广泛三维场景任务中具有巨大潜力。

图5: 人体姿态生成部分可视化结果
对于三维场景中的人体运动生成,SceneDiffuser 可以在三维场景中从相同的起始位置生成不同的动作(例如,“坐”、“走”),见图 6。

图6: 人体运动生成部分可视化结果
在灵巧手抓握生成的任务中,SceneDiffuser 在抓取成功率方面表现出更加显著的优势,且能够很好地平衡生成的多样性和抓取成功率。此外,通过优化引导采样减少不合理的抓取姿态,本文的方法优于当前最先进的基准模型,而无需进行额外的训练或中间表示。图 7 展示了一些 SceneDiffuser 生成的结果。
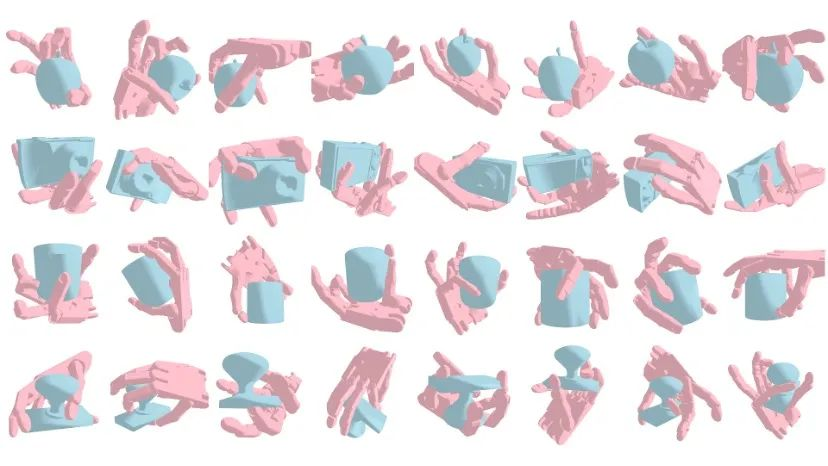
图7: 灵巧手抓握生成部分可视化结果
如表 1 中的定量结果所示,在室内导航路径规划和机械臂运动规划这两个任务中,SceneDiffuser 相比于基线模型获得了更高的成功率。这表明 SceneDiffuser 可以准确地结合场景条件下的轨迹分布和规划目标方面的知识,合理地调整规划方向,从而避免场景中的障碍和死角,成功地完成路径规划。
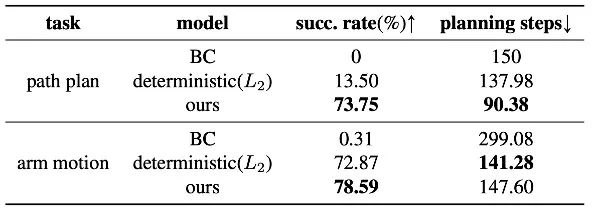
表1: 导航路径规划和机械臂运动规划的定量结果
有关更多的定量和定性分析及消融实验,请参见原论文和主页 https://scenediffuser.github.io/。
三、总结
本文提出了一个名为 SceneDiffuser 的通用条件生成模型,用于在三维场景中实现生成、优化和规划。通过将优化问题或规划问题的目标函数注入到扩散模型逆向过程中,SceneDiffuser 同时具备了场景感知式生成、基于物理的优化和目标导向的规划的能力,从而使它能够应用于广泛的三维场景理解任务。在五个任务上的定量和定性的实验结果表明,SceneDiffuser 远优于以往的模型,具有很大的有效性和灵活性。