人工智能领域国际顶级会议ICLR 2023即将在卢旺达首都基加利召开。本文是对北京通用人工智能研究院发表在ICLR 2023的论文“ SQA3D: Situated Question Answering in 3D Scenes ”的介绍。这项研究工作旨在联结三维场景理解和具身人工智能这两个领域,通过提出的具有丰富语义信息和推理任务类型的真实场景情境化三维场景问答任务(问答数据集SQA3D),对智能体的具身推理能力进行评估。
论文作者:马晓健,雍子隆(共同一作)郑子隆、李庆、梁一韬、朱松纯、黄思远;

项目链接:https://sqa3d.github.io/
一、研究背景
研究具身智能具有重要意义。人对世界的 “知” 是建立在 “行” 的基础上的,通用智能体想要真正进入物理场景和人类社会,其关键在于置身于真实的物理世界和人类社会中,只有这样它们才能切实了解并习得真实世界中事物之间的物理关系和不同智能体之间的社会关系,从而做到像人一样“知行合一”。近年来,构建具身智能体(embodied agents)的相关研究取得了长足的进步,包括在三维场景中进行基本的导航,物体操作等等[1] (图1)。但是不可否认的是,这些智能体在真实环境中,尤其是那些需要大量知识密集推理的环境(如家居环境)和任务上的泛化能力仍与预期有一定的差距。为了解决这一难题,本研究提出了一个新的研究方向:具身场景理解与推理(embodied scene understanding and reasoning),目标是通过在具身智能体的学习中引入更多的场景理解,以增强其在复杂的三维场景中的适应和决策能力。
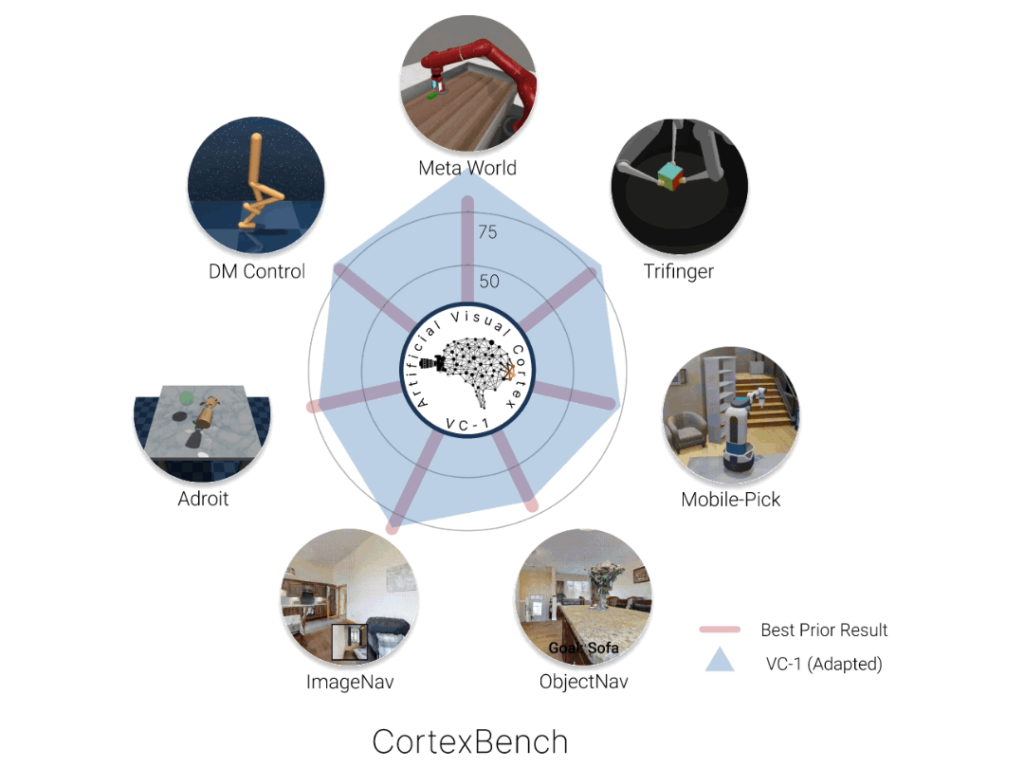
图1 具身智能体的典型任务来自CortexBench [1]
具身场景理解与推理可以被认为是具身智能体在进行决策前所需完成的必要步骤[2]:
首先,具身智能体需要根据任意情境描述(如文本)在三维场景中想象在该情境(具体表现为场景中的某个位置和朝向)下所能观测到的事物,并理解周边的环境;
其次,智能体需要在获取关于周边环境的信息和相关知识后进行有用的推理,从而为后续的规划任务提供支持。一个具体的例子如图2所示:在这样的一个家居环境中,当听到这样的情境描述 “putting my lunch in the microwave”(正在将我的午餐放进微波炉里),我们很容易能够想象出来这句话描述的场景大概是面朝微波炉的一个位置,有了这样的判断后,我们就能够很容易地完成一些相应的推理任务,比如 “which direction should I go to turn on the TV?”(我该往哪个方向走去打开电视?)——虽然电视机确实在身后,但是考虑到当前这个位置背后有桌子阻挡,我们需要先向右走避开这一障碍。诸如此类的问题对人工智能提出了新的挑战,同时也对具身智能体完成复杂的导航操作等任务具有重大意义。
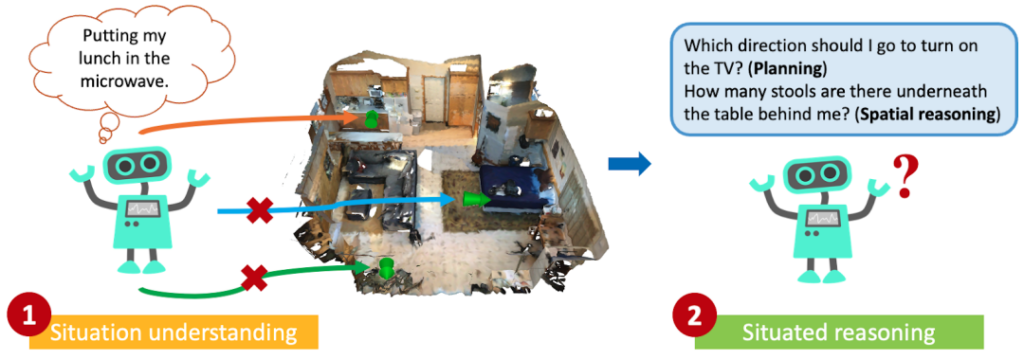
图 2 具身场景理解与推理
本文中,我们针对提出的具身场景理解与推理这一研究方向做出了尝试。我们首先引入了一个大规模的,具有丰富语义信息和推理任务类型的真实场景情境问答数据集——Situated Question Answering in 3D Scenes(SQA3D)。该数据集共包含650个场景下的20.4k条情境描述和33.4k个问题。相比于同类数据集(见图3), SQA3D 是目前为止规模最大,问题种类最多样,包含的场景和情境最为丰富的三维场景理解数据集。相比于同类的三维语言落地[4]和具身问答[3]数据集,SQA3D同时具备具身特性和极简的任务形式(仅包含定位和问答,不包含实际动作执行),可以称为是结合了许多现有数据集的优势于一身。
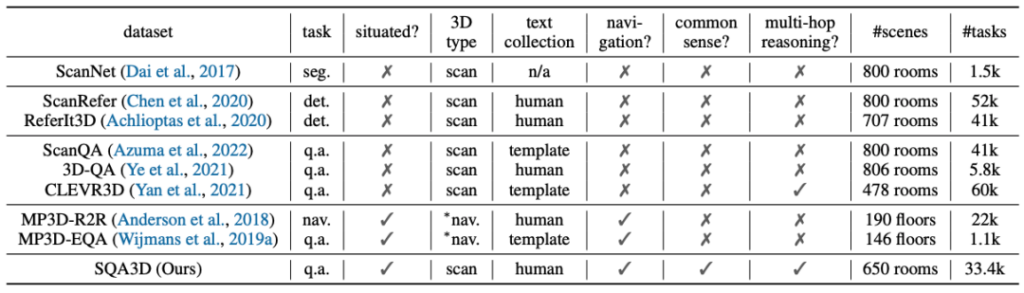
图3 SQA3D 数据集与同类数据集的对比
进一步的,我们对现有的AI模型,包括多模态模型和近期备受关注的大语言模型等在 SQA3D 数据集上进行了测试。实验结果表明,这些模型在具身场景理解与推理上与人类水平还有较大的差距,从而部分揭示了目前具身人工智能的缺陷和不足。
二、情境化三维场景问答(SQA3D)数据集
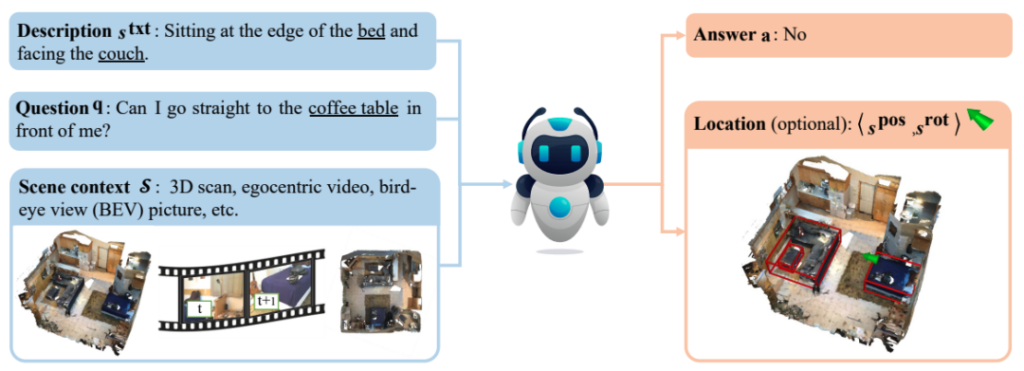
我们构建的SQA3D数据集本质上由三个部分组成(见图 4): ①三维场景,SQA3D 包含了对650个室内场景的多种表示方法,包括三维点云,第一人称视角的视频和鸟瞰图。数据集用户可以从中自由选择;②情境描述,标注员结合场景中的某个智能体(以绿色箭头标识)当前所处的位置(position)和朝向(orientation),以及周边的事物,对当前的情境进行描述。为使相关描述更加自然,标注员被引导使用日常的活动来进行描述,譬如“I am waiting my meal to be heated in the microwave” (我在等微波炉热好我的午饭)而不是“I am in front of the microwave”(我在微波炉前方)这样相对比较机械化的描述方式;③问题采集,标注员会被虚拟的置身于每个情境下,并针对当前的周边环境进行提问。
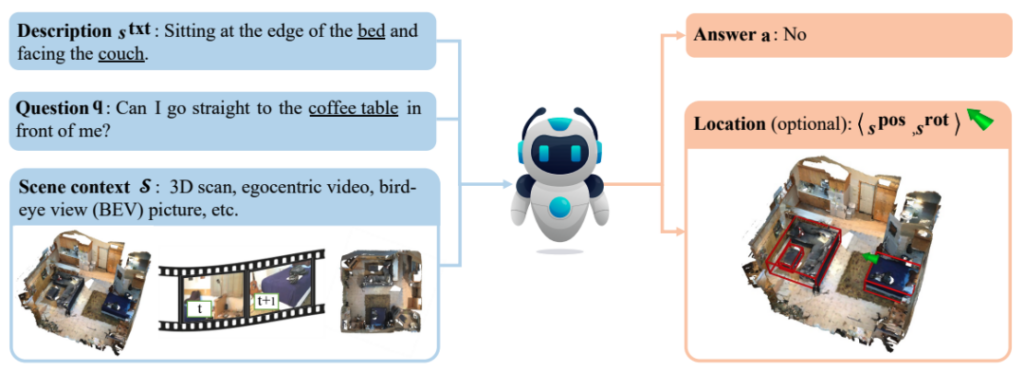
图4 SQA3D 数据集的组成
为保证标注质量,SQA3D 对于标注员可以提出的问题有一定的要求。与当前情境无关的问题,比如“how many chairs are there in the whole room?”(房间内有几把椅子?)是不被允许的,因为回答这种问题不需要考虑当前的情境,而“how many chairs are there behind me?”(我后面有几把椅子?),则可以被接受。同时,标注员会被引导提出需要进行复杂推理的问题(例子见图5),包括导航,常识,多跳推理等等。这些都极大的保证了数据集的问题的丰富性和语言的多样性,具体可见图6 左中给出的数据集中情境描述的词云,以及图6右中问题的前缀分布。
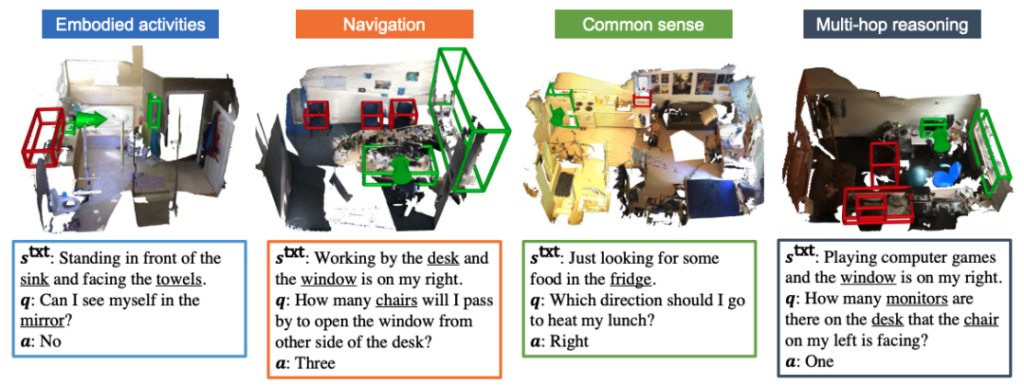
图5 SQA3D 数据集的一些例子
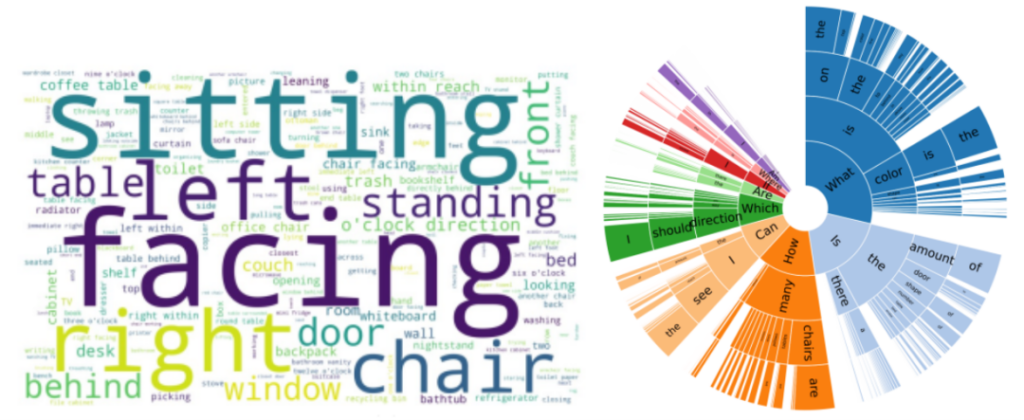
图6 SQA3D 数据集的统计信息
三、评估现有AI模型的具身推理能力
基于SQA3D 数据集,我们希望对当前主流AI模型的具身场景理解和推理能力进行评估。我们主要希望回答的科学问题是:当前的多模态和推理AI模型,在这个新任务上与人类水平的差异有多大?考虑到从根本上SQA3D是一个 3D-language 多模态的问答数据集,我们因此选择了目前最佳水平的多模态推理模型进行测试,包括ScanQA[4] (使用三维点云输入),ClipBERT[5](使用第一人称视频输入)和MCAN[6](使用鸟瞰图输入)。于此同时,我们也希望测试一下当下大热的大语言模型如GPT-3[7] 的强大推理能力能否帮助解决这个新的问题。为了将三维场景桥接到这类语言模型上,我们借助了场景字幕生成[8]的方法将三维场景转化为文本描述,从而作为prompt的一部分去调用大语言模型来回答提问。图7展示了这类模型的更多细节。
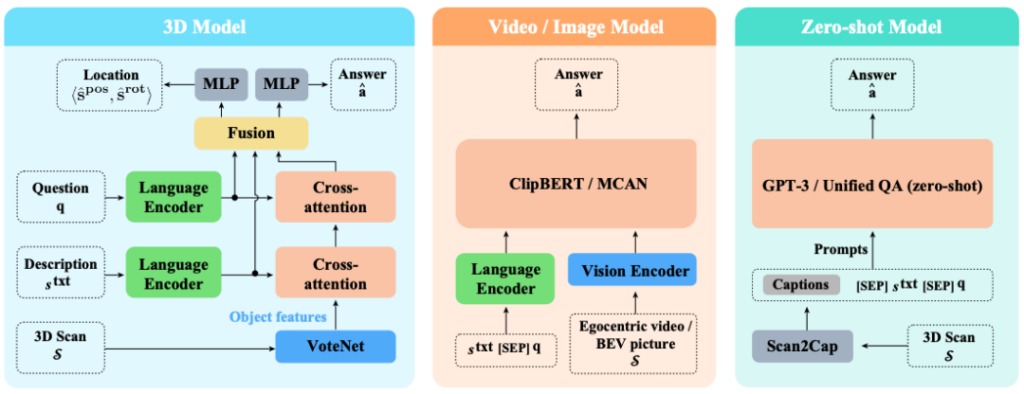
图7 在SQA3D上进行测试的模型
我们从定性和定量的实验中观察到了以下的现象:
①情境理解(situation understanding)在完成SQA3D任务上起到至关重要的作用。在有关ScanQA模型的三个实验中,我们在标准设定外新增了将情境文本去除(亦即完全消除情境理解的能力)和引入额外的情境理解损失函数(在回答问题外,额外的预测当前智能体所处的位置和朝向)这两组实验,结果表明消除情境理解后模型的性能出现明显下降,而情境理解损失函数则有助于取得更好的问答性能。
②三维场景表示对场景理解有明显影响。对比ScanQA,ClipBERT和MCAN,使用三维点云作为输入的ScanQA要明显优于另外两个模型。由此可见在目前的模型下,使用三维点云表示场景仍然在场景理解任务上有一定的优势。③大语言模型有很强的具身推理潜力,但是仍然会被单一模态所限制。结果中可以看出,虽然大语言模型(UnifiedQA 和 GPT-3)整体上的表现欠佳,但是在某些问题类别上能达到当前的最佳性能。进一步的,当我们调整场景字幕生成的方式时,实验结果也会发生显著的变化,这表明借助模态翻译的大模型会受制于自身无法理解语言之外的模态这一短板。
④现有模型与人类差距仍然明显。即便是未经过专业培训的人类测试员也能轻松地在SQA3D上取得90+的准确率,与目前最好的模型(47.2%)差距巨大,表明当前的模型在很多方面仍然有改进的空间。
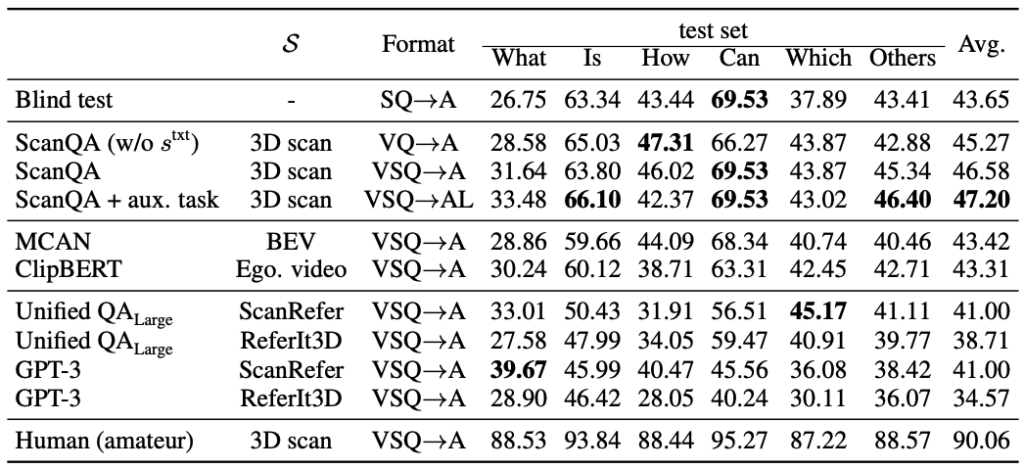
图8 定量实验结果
进一步的,定性实验结果揭示了注意力机制的重要性。我们将注意力最高的物体用红框标出,可见当模型能正确地注意到关键物体时,更容易最终得到正确的答案。
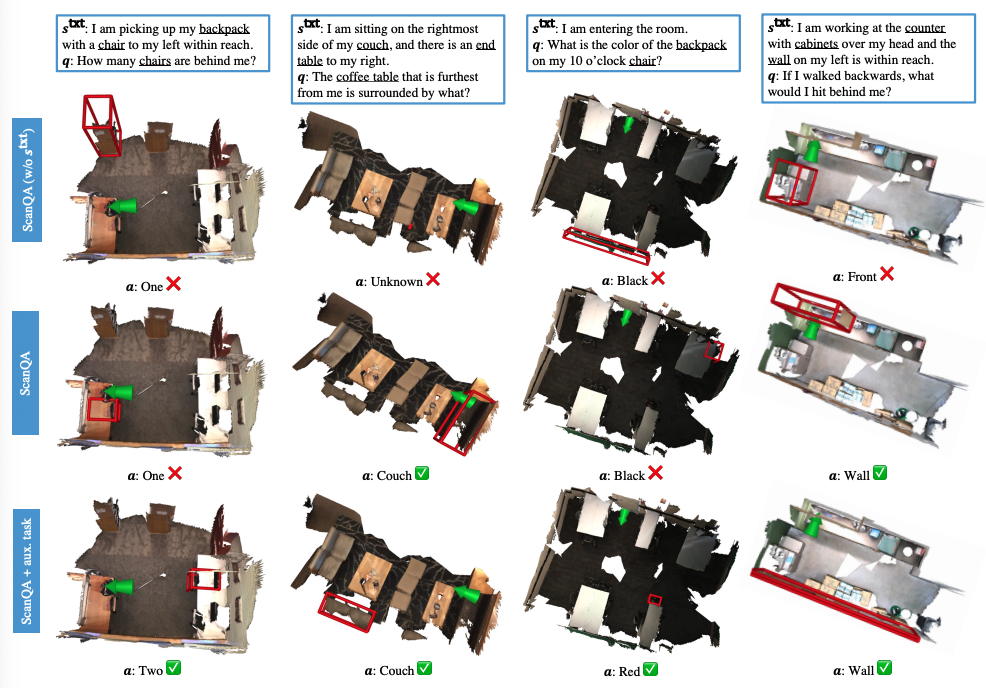
图9 定性实验结果
四、总结
我们在本项工作中针对当前具身智能和场景理解这两个领域的问题,提出了一个新的人工智能任务:具身场景理解与推理(embodied scene understanding and reasoning),并构建了包含丰富场景和问题标注的SQA3D数据集。SQA3D 提供包括点云、第一人称视角视频和鸟瞰图在内的多种场景表示和大量知识和推理密集的问题,为当前的人工智能模型提出了极大的挑战。SQA3D 的一个目标是通过联结场景理解和具身智能,帮助我们更好地理解当前的具身智能体的缺陷和不足,并展示通过结合更好的场景理解来改善其相关能力的途径。希望我们的工作能为下一代具身智能体的研究工作提供一些启发。