
随着生成式人工智能技术的飞速发展
合成数据正日益成为大模型训练的重要组成部分
未来的GPT 系列语言模型不可避免地将依赖于
由人工数据和合成数据混合构成的大规模语料
然而,这一趋势也带来了严峻挑战:
合成数据如果不加控制地使用
可能引发“模型崩溃”(Model Collapse)问题
即便仅在一次训练中混入较多比例的合成数据
也可能导致模型性能急剧下降
难以泛化到真实世界的数据中[1,2]
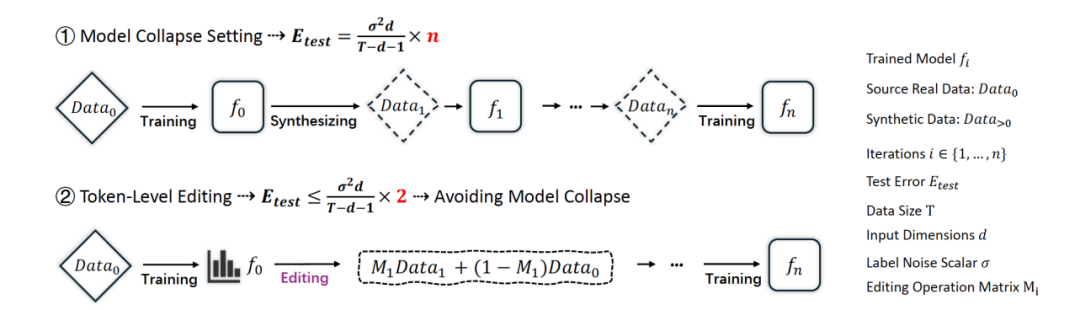
在 ICML 2025 上,北京通用人工智能研究院(简称“通研院”)提出了一种创新的数据增强范式——Token-Level Editing。不同于直接使用生成数据,该方法在真实数据上引入细粒度的“微编辑”操作,从而构建出结构更稳定、泛化性更强的“半合成”数据,有效规避了模型崩溃风险。
”
论文标题:How to Synthesize Text Data without Model Collapse?
论文链接:https://arxiv.org/pdf/2412.14689
第一作者为通计划联培学生朱学凯

非迭代式模型崩溃现象识别 为揭示合成数据对语言模型训练的深层影响,研究团队系统性地分析了在不同合成比例条件下的模型表现。实验结果显示:即使只进行一次性预训练,在训练数据中混入高比例的合成样本,仍会显著降低模型性能。这种现象被称为非迭代式模型崩溃(Non-iterative Collapse),它打破了人们对“模型崩溃仅在反复迭代中出现”的传统认知,并在多个语言理解任务中得到了一致验证 [3]。
具体而言,研究在预训练模型上进行了大量实验,构造了合成与真实数据不同比例混合的数据集,覆盖包括数学、图书、法律、医疗、新闻、社交等22个语料子领域。模型在这些子任务上的困惑度(PPL)随着合成数据比例的提升而显著上升,表现出稳定的性能退化趋势。
更关键的是,即使保留一部分真实数据,只要合成数据占比达到一定程度,也难以完全抵消其带来的负面影响。这一现象表明:当前主流合成数据生成策略在数据质量和分布多样性上仍存在显著缺陷,无法胜任高质量语言模型的预训练任务[4]。
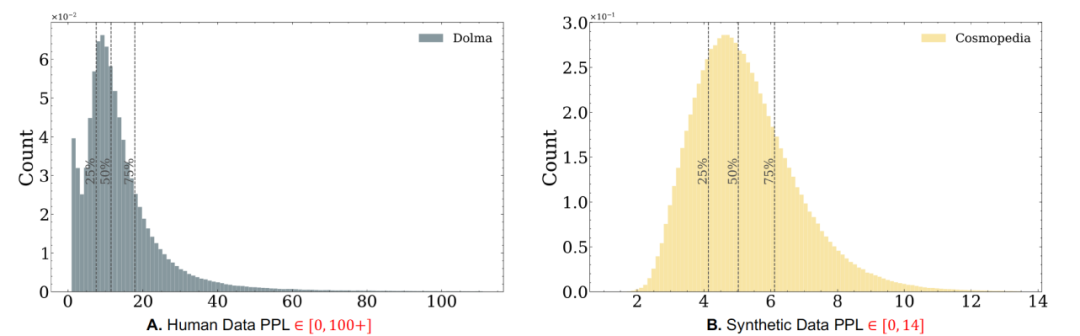
合成数据的分布缺陷分析: 覆盖收窄与特征集中过度 为了进一步探究模型崩溃背后的根本原因,研究团队对比了合成数据与人工数据在统计层面的分布特性。分析发现,合成数据在结构上存在以下两类核心缺陷: 分布覆盖收窄: 合成数据普遍缺乏低频和长尾样本,这意味着它未能覆盖自然语言中真实存在的多样语义表达。这种覆盖范围的收窄,限制了模型对复杂场景、少见语言模式的泛化能力,导致模型训练后“理解力变窄”。 特征密度过高: 从 n-gram 等语言特征维度来看,合成数据往往表现出明显的特征重复性,高频模式密集、表达结构趋同。这种“过拟合式的表面丰富”,实质上会加剧模型对局部规律的学习,反而降低其对真实语言变化的适应性。最终,模型易陷入“记住合成伪样本、误判真实样本”的困境。
在多个主流语料(如 Wikitext、Redpajama、c4-en 等)上,随着训练数据中合成比例增加,模型的困惑度曲线出现一致的上升趋势,显示其学习能力受限。
这说明:并非所有合成数据都有益,质量低或分布偏离的合成数据反而可能“毒化”模型训练过程。如何在生成机制中引入分布控制与语言多样性保护,成为当前语言模型发展中的关键挑战。
Token-Level Editing:以编辑替代纯生成 更精细、更高质量的数据生成方式 为了解决大规模语言模型在使用合成数据训练时容易出现“模型崩溃”的问题,研究团队提出了一种全新的数据增强策略 —— Token-Level Editing。其核心理念是: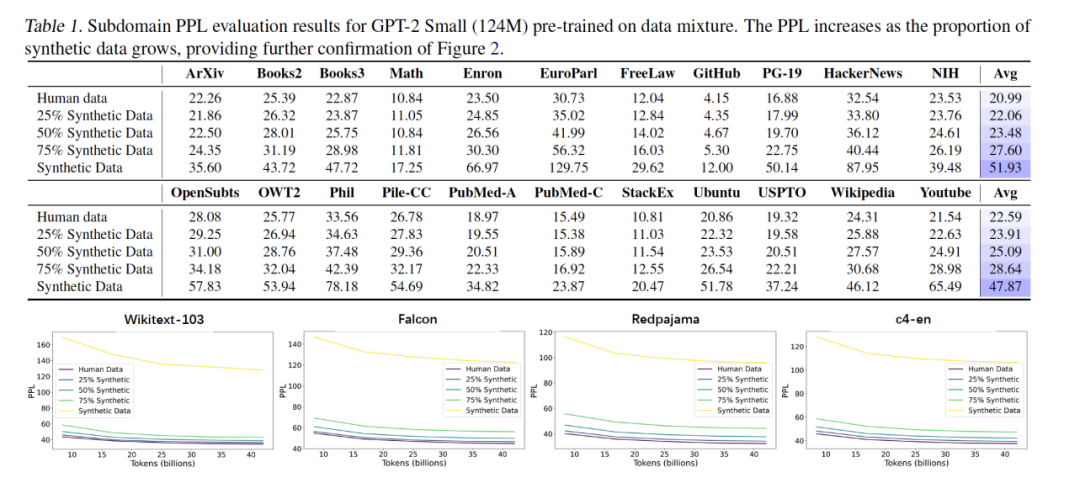
不直接合成整段文本,而是在模型“过度自信”的位置进行精细化的 token 级别替换操作,从而在保留原始数据结构的同时实现更自然、更多样的数据增强。
”
这种方法的关键在于,它不仅继承了真实数据的自然分布特性,同时避免了合成数据中常见的重复模式和单调结构,从而增强了模型对语言多样性的理解能力。
具体实施过程包括:
-
使用预训练语言模型对训练样本中每个 token 的生成概率进行估计,衡量哪些位置“过于容易”;
-
对那些预测概率超过设定阈值(如 p = 0.99)的 token,进行重新采样,以打破过度重复的表达结构;
-
对置信度低的 token 则保留不变,从而保留原始数据中的难点、边缘样本和长尾分布,提升模型的泛化能力。
通过这种方式生成的数据不再是“凭空虚构”,而是基于真实样本的微调重塑,兼具可信性和多样性,是合成数据利用的新范式。
理论结果:测试误差有固定范围,避免模型崩溃
为了进一步验证方法的稳健性,研究团队还从理论角度进行了深入分析。我们构建了一个数学上的回归分析框架,并推导出结论:Token-Level Editing 过程中模型的误差不会随着训练轮数持续积累,而是始终被限制在一个固定的范围内。
这与传统合成数据方法形成鲜明对比。过去的研究已经发现,使用模型自己生成的数据进行迭代训练,会导致“越训越偏”,最终模型无法泛化到真实世界。这种现象被称为“模型崩溃”。
相比之下,Token-Level Editing 只对数据中一小部分 token 进行有选择性的替换,避免了数据分布的大幅漂移。无论训练多少轮,模型始终能够维持对原始数据分布的覆盖,保持其对真实语言的理解能力。
研究表明:
-
这种方法能从数学上阻止误差无限增长的趋势;
-
同时在实验中也展现出更稳定、可控的训练表现;
-
是一种兼具理论可靠性与实践效果的技术路径。
因此,Token-Level Editing 不仅是解决当前合成数据困境的一种创新方法,更为构建更加安全、高效、可靠的语言模型训练体系提供了坚实基础。
实验结果:从预训练到微调全面验证方法有效性
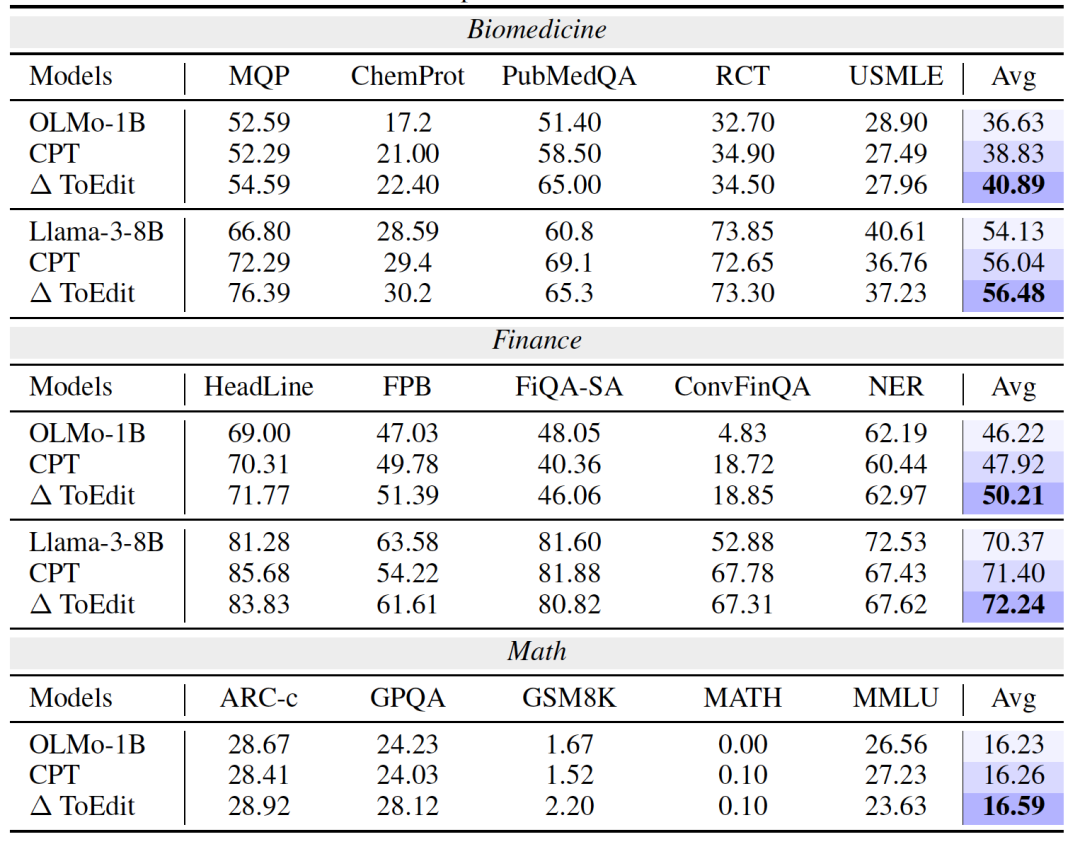
为全面验证 Token-Level Editing 的有效性,研究团队在语言模型训练的三个关键阶段进行了系统实验:
-
预训练阶段(Pre-training):在通用任务如 PIQA、BoolQ、Winogrande 等 benchmark 上,模型在引入编辑数据后表现持续优于纯合成数据方案。例如在 OLMo-1B 上,整体任务平均分提升了 +0.36 个百分点。
-
持续预训练阶段(Continual Pre-training):在生物医药、金融、数学等专业任务中,Token-Level Editing 带来了跨域的泛化提升。例如在 PubMedQA 任务中,准确率提升高达 +13.6%。
-
监督微调阶段(Supervised Fine-tuning):在指令理解与代码推理等复杂任务中,编辑数据同样展现了对多样语言指令的强鲁棒性。以 LLaMA-3 为例,平均提升 +0.4~0.5%,且在多个任务上保持一致性优势。
此外,为验证方法的稳健性,研究还进行了多轮消融实验,包括:
-
编辑阈值 p 的变化范围;
-
多种采样策略(Top-k、Top-p、拒绝采样);
-
不同 token 置信度分布下的替换比例。
结果显示:在不增加训练数据规模的前提下,该方法依然具备良好可控性与可迁移性,具备强大的实际落地潜力。
总 结
在训练下一代 AI 模型时,混合使用合成数据与人类生成的数据已成为不可避免的趋势。因此,我们关注两个关键问题:(1)合成数据对语言模型预训练的影响及其潜在原因是什么?(2)如何防止模型崩溃并合成高质量数据?我们发现,合成数据在与人类生成数据混合时会削弱预训练效果,导致非迭代式的模型崩溃。统计分析表明,合成数据存在显著的分布偏差,并且 n-gram 特征过于集中。对此,我们提出使用基于训练先验的token级编辑方法,而非仅依赖于纯合成数据,该方法能够防止模型崩溃,在预训练、持续预训练以及监督微调任务中,我们的方法均优于原始数据。
/参考文献 /
[1] AI models collapse when trained on recursively generated data. *Nature* 631, 755–759 (2024).
[2] A tale of tails: model collapse as a change of scaling laws. ICML’24
[3] Collapse or Thrive? Perils and Promises of Synthetic Data in a Self-Generating, arXiv, 2024
[4] Position: Model Collapse Does Not Mean What You Think. 2025.
北京通用人工智能研究院
