人形机器人正逐步迈向具身智能的新阶段
仅仅完成任务已无法满足人类对其认知能力的期望
如何在执行任务的同时理解并尊重人类偏好
是具身智能发展的关键
北京通用人工智能研究院(简称“通研院”)
与河海大学共同提出
首个结合人类偏好与物理约束的统一框架——ICLHF
使机器人在完成任务时能够权衡两者
展现出更符合人类预期的行为模式
推动机器人的能力从“会做”向
“做得对、做得好”跃迁

相关研究成果已被IROS2025会议接收,论文作者是河海大学博士、通研院实习生李洪涛,通研院研究员焦子元,共同通讯作者是河海教授刘小峰、通研院研究员刘航欣、郑子隆。
项目主页:https://iclhf.github.io
成果概览 得益于大语言模型(LLMs)的能力提升,具身智能体在执行复杂任务方面取得了显著进展。然而,对于认知型机器人而言,仅仅完成任务远远不够,其还应理解并融入人类偏好,在满足物理约束的前提下,做出更具人性化的行为选择。
本文提出一种结合人类偏好和物理约束的统一框架,引入“人类反馈上下文学习(ICLHF)”方法,支持机器人在实际交互中从人类的直接指示或间接调整中学习偏好。为验证方法的有效性,研究构建了一个以家庭日常任务为核心的评测基准,并通过大量仿真与真实机器人的实验证明,ICLHF能够有效生成任务计划,在偏好遵循与物理可行性之间实现平衡。
研究方法 教会机器人在执行任务的同时理解并尊重人类偏好需要解决以下两个挑战:
如何学习人类偏好?现有方法,例如RLHF[1](Reinforcement Learning from Human Feedback,来自人类反馈的强化学习),依赖于大量人工标注的数据,且此类基于比较的方法也难以描述人类偏好的多样性。 如何将人类偏好和物理约束结合起来?物理约束是明确且通用的,然而,人类偏好往往难以预测、各式各样,目前缺少一种合适的方法将两者有效地结合起来。
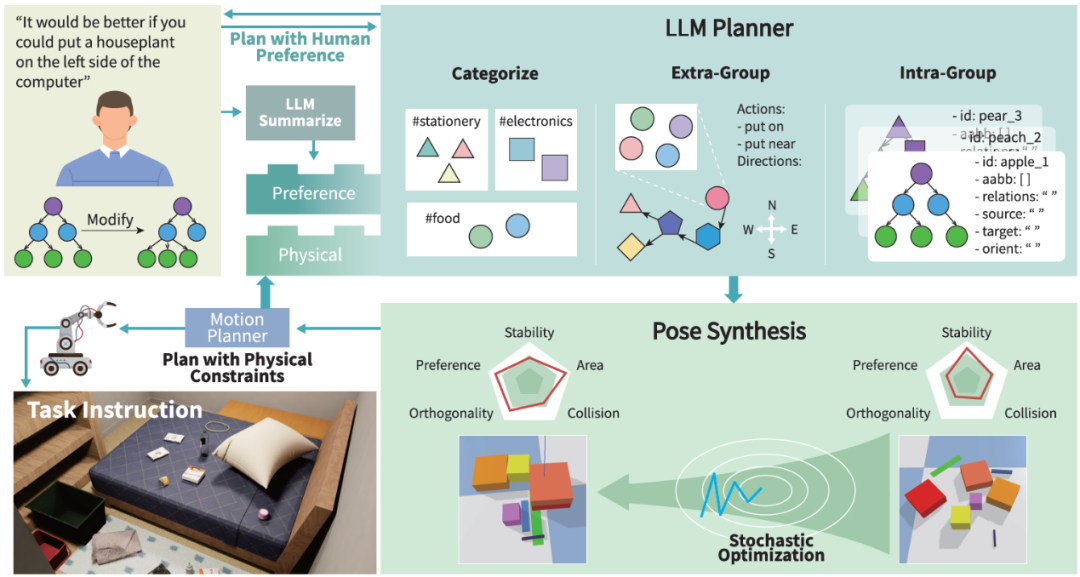
为解决上述挑战,本文提出了“人类反馈上下文学习(In-Context Learning from Human Feedback)”ICLHF方法,其中包括两个部分:大语言模型规划器和姿态合成器。大语言模型规划器通过上下文学习的方式学习人类偏好,该偏好以文本形式表示,使之能够有效地结合物理约束,从而生成目标场景图。随后使用基于POG[2](一个在场景图上进行顺序操作规划的算法)的姿态合成器对前者生成的场景图进行完善,填充关于物体位置、旋转等细节信息。在整体流程中,新的物理约束以及人类偏好能够及时以反馈的形式注入大语言模型的规划中,以便后续任务的更新与调整。 图 1:ICLHF方法框架,包括两个部分: 大语言模型规划器(右上)和姿态合成器(右下)
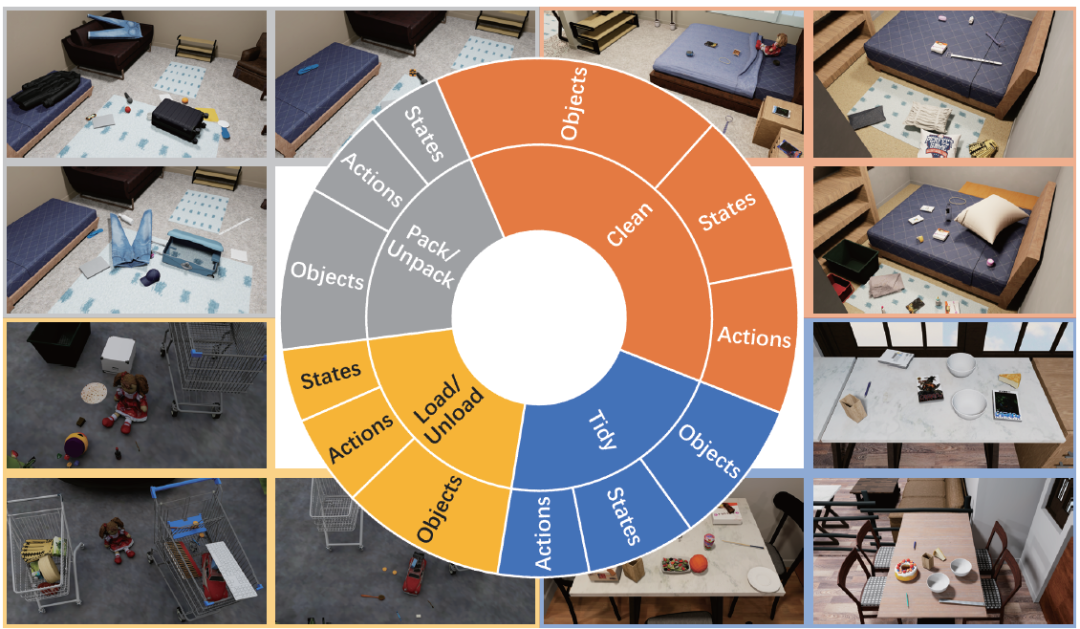
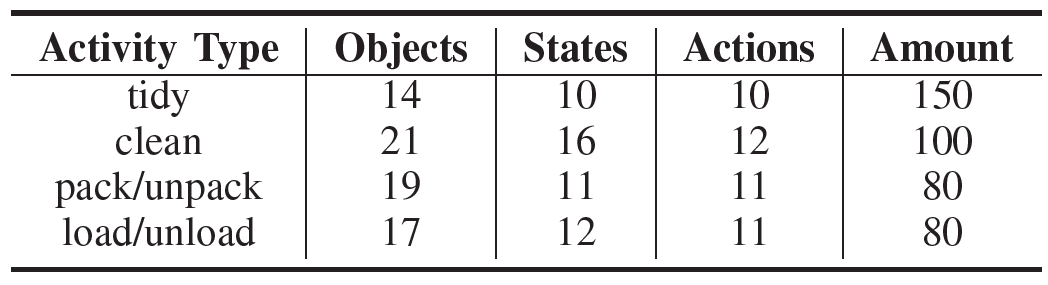
为验证ICLHF的有效性,本文基于Behavior-1K[3](一个关注于人类实际需求的日常活动基准)构建了ICLHF基准,该基准涵盖了四类典型的涉及人类偏好的日常活动:收拾整理、打扫清洁、打包/开箱以及装载/卸货。对于每一类活动,都提供了默认的人类偏好,该偏好被精心设计以使其(1)在当前场景下至少存在一种解法;(2)对于任务完成的影响有易有难;(3)具有一定的泛化性,能够影响到其他活动,从而极大地丰富了场景偏好的多样性。关于偏好的评估包括主观和客观评分两种方式,主观评分由人类受试者对生成的结果给出0~10分的结果,客观评分和对应设计好的偏好互相绑定,加权统计每个受影响物体的关系与姿态。 图 2:ICLHF基准 涵盖四类典型的涉及人类偏好的日常活动 表 1:四类活动及其属性
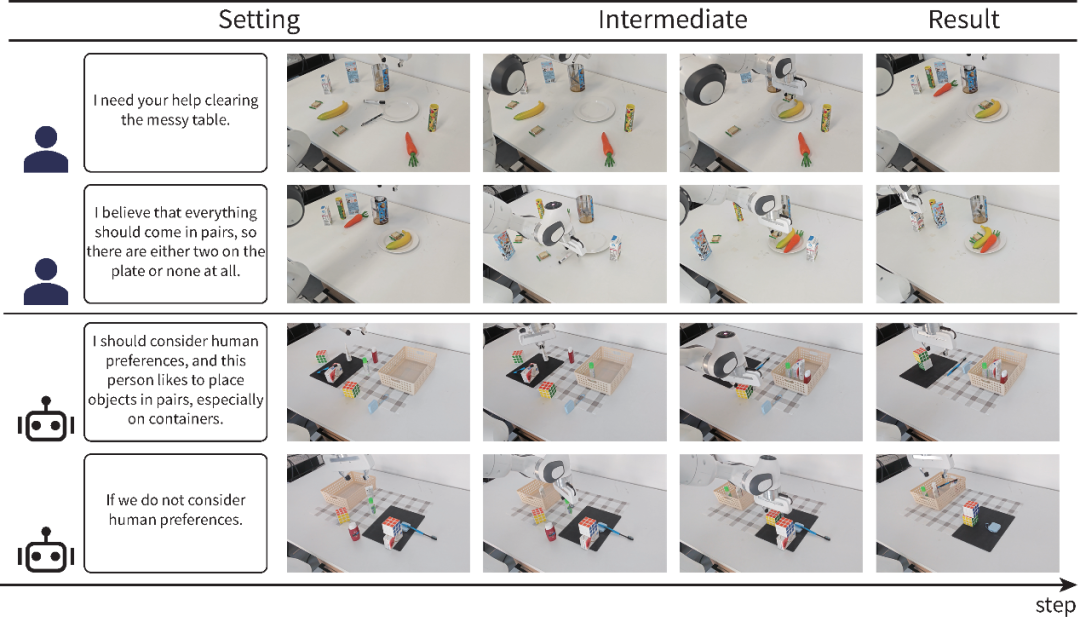
实验结果分析 本研究在OmniGibson[3]仿真平台上测试了ICLHF方法,测试任务来自ICLHF基准。为了提高实验的复杂性,部分测试结合了多种人类偏好,例如下图中第四行的收拾房间任务,集成了前三行任务的偏好,这能更好地分析算法如何在更加真实的场景下平衡复杂偏好和物理约束。实验结果表明ICLHF方法能够在完成任务的同时平衡好人类偏好和物理约束。 图 3:仿真平台实验结果
在真实环境下,ICLHF方法同样展现出了强大的泛化性,下图展示了实验结果。通过明确指定人类偏好,ICLHF能够及时调整已有规划,在物理约束和偏好之间取得平衡,同时,面对后续全新的场景,也能够利用先前学习到的偏好指导规划。 图 4:真实环境实验结果
总结展望 本研究提出了一种融合物理约束与人类偏好的统一框架ICLHF(人类反馈上下文学习),能够在执行过程中学习个性化偏好,并生成既满足物理可行性又贴合人类需求的规划方案。为评估方法效果,构建了一个引入人类偏好的新型基准测试,并在多个维度上进行了实验验证,结果证明ICLHF能够很好地平衡物理约束与人类偏好。最后真实机器人的实验进一步表明,ICLHF具备良好的现实应用能力和泛化性。
/参考文献 /
[1] Ouyang L, Wu J, Jiang X, et al. Training language models to follow instructions with human feedback[J]. Advances in neural information processing systems, 2022, 35: 27730-27744.
[2] Jiao Z, Niu Y, Zhang Z, et al. Sequential manipulation planning on scene graph[C]//2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2022: 8203-8210.
[3] Li C, Zhang R, Wong J, et al. Behavior-1k: A benchmark for embodied ai with 1,000 everyday activities and realistic simulation[C]//Conference on Robot Learning. PMLR, 2023: 80-93.
北京通用人工智能研究院