
智能体的进化离不开学习使用工具的能力
在面对复杂、多变的真实世界多模态任务
如何让智能体快速高效地学会工具使用
并实现能力跃迁
一直是多模态智能体的核心挑战
通研院与北大、北理工等单位
共同提出首个多模态智能体微调方法——MAT
自动生成高质量多模态任务和轨迹数据
大幅度提升智能体的推理和工具使用能力
让智能体更准确调用工具库和知识库
更好地完成真实世界中用户的指令

-
论文链接:https://arxiv.org/pdf/2412.15606
-
第一作者:通研院研究员高志、通研院算法工程师张博飞、北理工通计划学生李朋祥
-
共同通讯作者:通研院研究员李庆、北理工教授武玉伟
成果概览 利用大语言模型(LLMs)调用外部工具,是数字智能体解决复杂多模态任务的一种可行途径。目前已有研究通过提示工程为大语言模型提供解决具体任务的示例,但在面对具有多种模态信息、求解轨迹复杂的任务时,往往能力有限。智能体的推理、规划能力还需进一步提升。
本文提出全新的智能体微调方法,包括一个高质量轨迹数据收集策略、一个智能体轨迹数据集和一个T3 数字智能体。该策略自动生成多模态工具的使用轨迹,为智能体数据匮乏的问题提供一套切实可行的方案。基于该策略,获得了由2万条高质量轨迹数据组成的MM-Traj数据集,可被其他智能体直接使用。最后,使用该数据集来微调视觉语言模型(VLMs),提升其推理、规划、使用工具的能力,并获得T3数字智能体,大幅度提升已有开源智能体的性能。
研究方法 为解决已有智能体在推理规划能力上的局限,本文探索了如何自动生成多模态工具的使用轨迹数据,并调优视觉语言模型(VLMs)作为控制器,以实现强大的工具使用推理能力。在此过程中,本文解决了两个挑战问题:
挑战一:收集多模态任务 现实世界中的任务通常涉及多个工具和多个文件(图像、文本文件、视频、音频等)。现有的数据集很少,且通过提示模型生成自然且多样化的任务并非易事。 挑战二:生成高质量任务求解轨迹 由于轨迹的复杂性,已有方法通常手动定义模板并填充关键信息以生成轨迹[2]。这限制了合成数据的多样性,并导致对真实世界任务的弱泛化能力。
为克服上述挑战,本文提出了一种新颖的工具使用数据合成策略,通过三个步骤自动生成大量多模态工具使用轨迹数据:查询生成、文件生成和轨迹生成。具体来说,本文首先利用GPT-4o mini和通过头脑风暴获得的任务实例生成大量任务描述。接着分析解决任务所需的文件,本文从已有的图像数据集中搜索图像数据,或提示GPT-4o mini生成代码以生成所需的文件。最后,利用一个零样本智能体求解所生成的任务并收集轨迹,包括任务求解过程中的规划和代码。为保持数据质量,生成的任务和轨迹通过两个验证器以丢弃低质量数据。 图:智能体数据生成策略示意图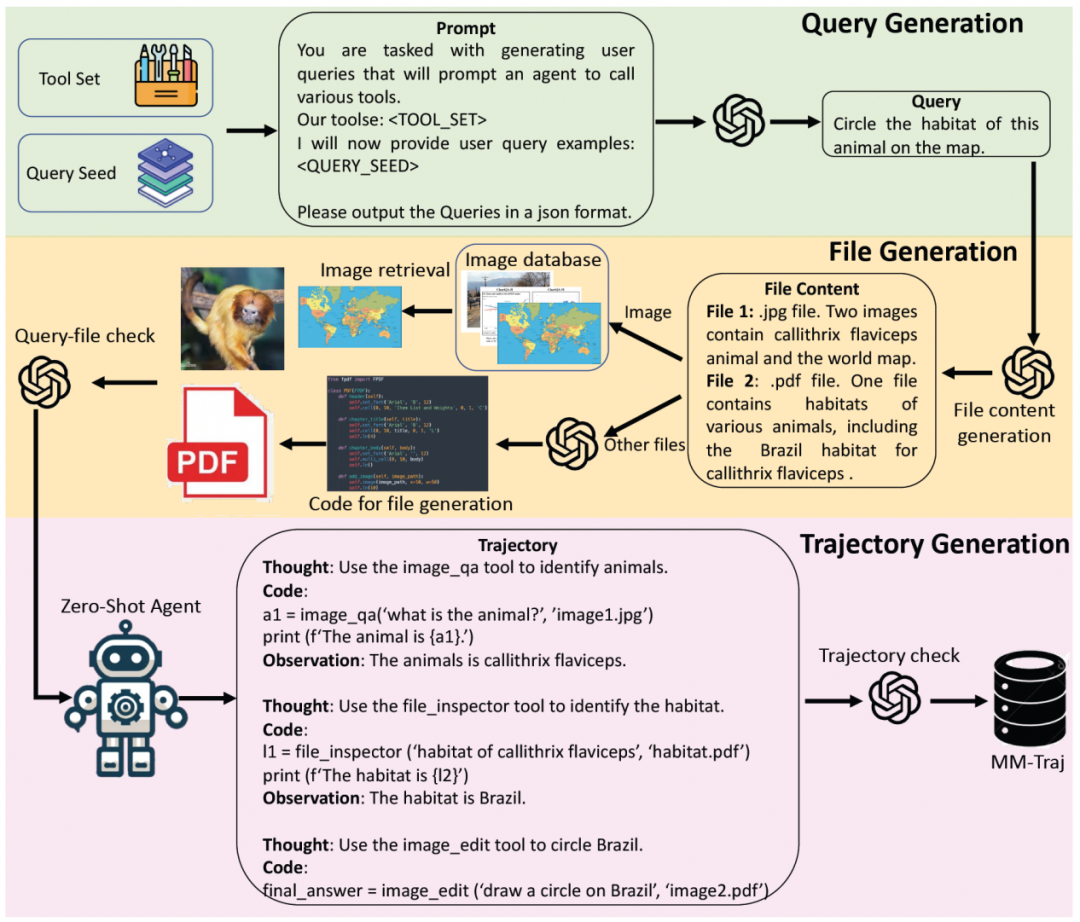
通过数据生成策略,本文构建了MM-Traj数据集,包含2万个多模态任务及其工具使用轨迹。如下图所示,数据集涉及多样的文件类型和知识领域。在使用工具方面,网络搜索工具是最常用的工具,这与需要特定知识的实际任务一致。此外,其他工具在我们的数据集中也被广泛使用。最后,本文也展示了轨迹数据中的步骤数分布。MM-Traj数据集中的轨迹具有多样化的步骤数。大多数任务需要2-6步来解决,一些任务需要7-8步,展示了数据集的复杂性和多样性。 图 MM-Traj数据集分析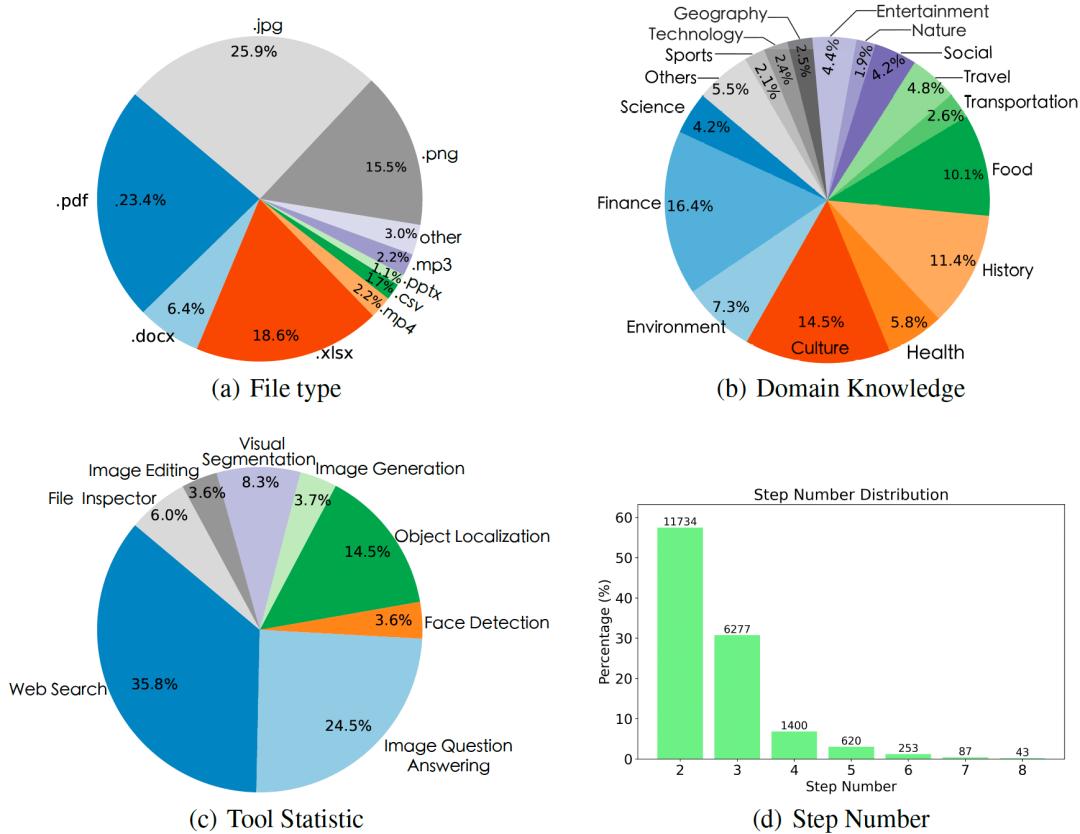
基于MM-Traj,本文训练了T3智能体中的VLM控制器。MM-Traj中的每条多模态工具轨迹数据包括多模态文件、文本形式的任务、生成的思考(即调用工具的计划)、生成的代码、观察(使用工具的输出)以及真值答案。本文使用交叉熵损失训练VLM控制器。
实验结果分析 为评估所提出的多模态代理调优方法的有效性,本研究在GTA[3]和GAIA[4]测试基准上评估了T3智能体。本文使用MiniCPM-V-8.5B模型和Qwen2-VL-7B模型初始化VLM控制器。智能体在GTA和GAIA测试基准上的性能如下表所示。T3智能体中,微调过的VLM相比于未微调的 VLM取得了显著提升。相比于已有的开源模型,T3智能体同样取得了更优的性能。 表 GTA测试基准上的实验结果
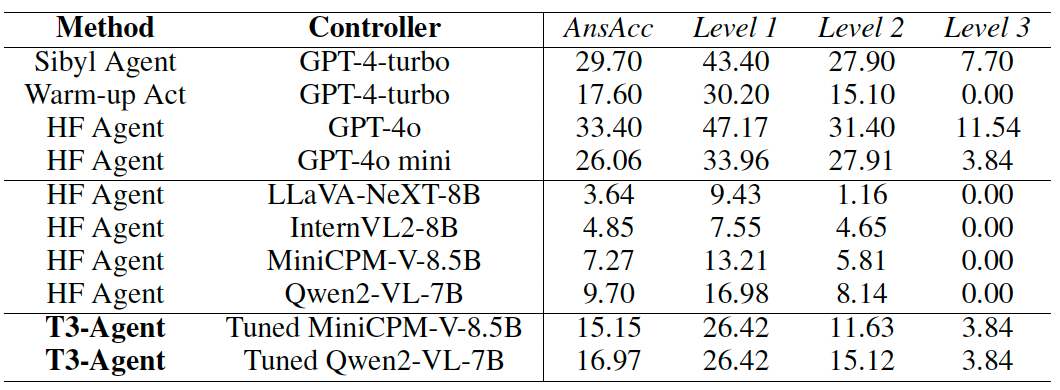
表 GAIA测试基准上的实验结果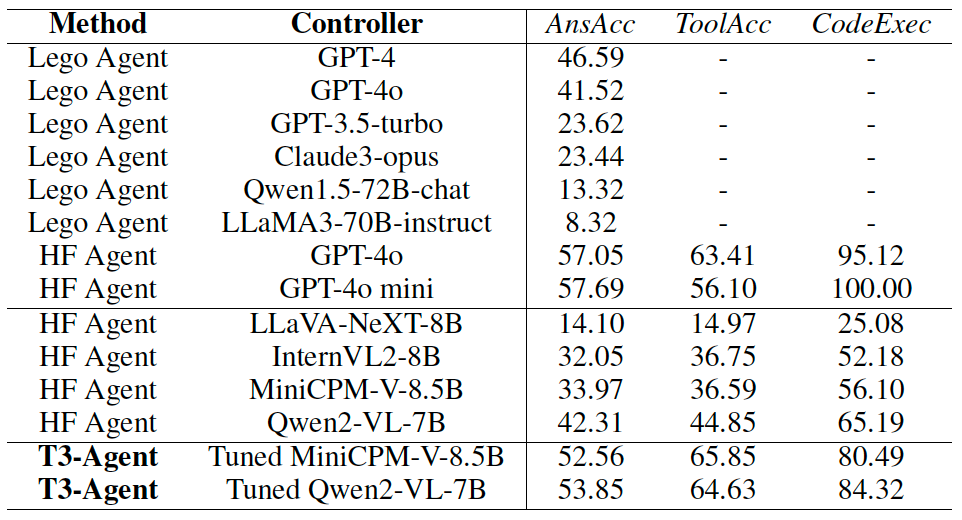
在下图中,本研究可视化了T3智能体在求解多模态任务的案例。T3智能体可以处理多图像推理任务,通过利用给定图像中的视觉信息,智能体可以使用合适的工具并填写正确的参数。T3智能体可以解决多跳问题,处理音频和PDF等多模态文件。 图 T3智能体求解任务示例
下表展示了智能体随着数据集规模的增加的尺度定律。随着数据量的增加,智能体的性能有所提升,内存消耗保持恒定,而时间消耗则呈线性增长。与准确率的提升相比,内存和时间的消耗是可以接受的。 表 T3智能体的数据量尺度规律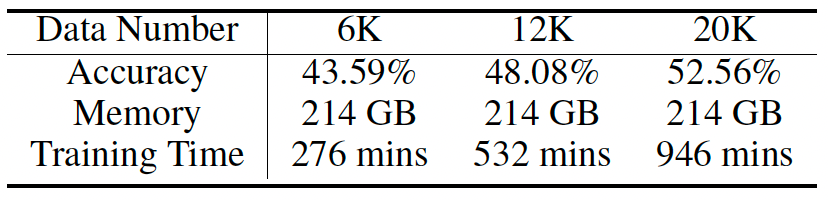
总结展望 本研究所提出的智能体微调方法可以有效生成大量工具调用的轨迹数据,并使用这些数据来调优VLM控制器,提升智能体的推理规划能力。调优后的控制器在两个多模态基准测试上取得了显著改进,证明了智能体微调方法和数据合成策略有效性。
当前的智能体数据只考虑了任务中的多模态信息,但在求解任务的轨迹中同样存在多模态信息,例如图像编辑任务的中间结果。未来,我们将研究如何利用智能体轨迹中的多模态信息,实现更强大的逐步推理,来调用多样的多模态工具。
目前,该研究已集成至TongAI,为全球首个通用智能人“通通”的推理、学习提供支持。“通通”接受真实世界的反馈,自动生成高质量任务和轨迹数据,并通过自我学习来更新推理模块。该研究帮助“通通”更准确地调用工具库和知识库,更好地完成人类的指令,实现与真实世界的自然交互。 图 智能体微调项目应用至“通通”示意图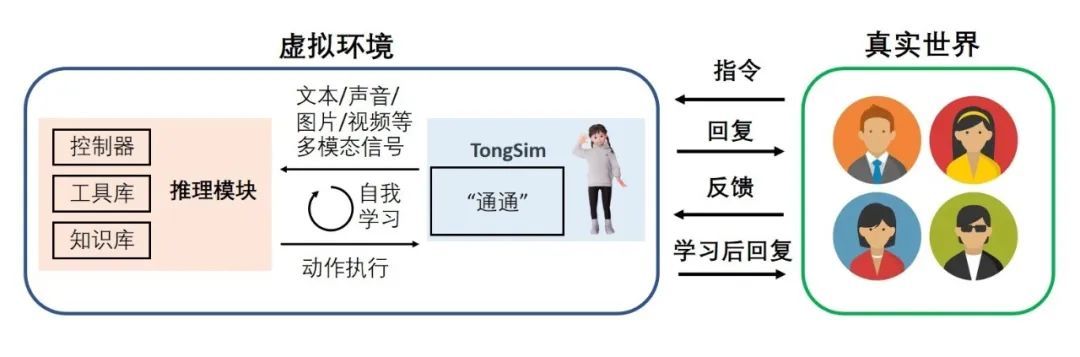
/参考文献 / [1] Gao Z, Zhang B, Li P, et al. Multi-modal Agent Tuning: Building a VLM-Driven Agent for Efficient Tool Usage. International Conference on Learning Representations, 2025. [2] Liu X, Zhang T, Gu Y, et al. Visualagentbench: Towards large multimodal models as visual foundation agents[J]. arXiv preprint arXiv:2408.06327, 2024. [3] Jize Wang, Zerun Ma, Yining Li, Songyang Zhang, Cailian Chen, Kai Chen, and Xinyi Le. GTA: A benchmark for general tool agents. In Advances in Neural Information Processing Systems, 2024. [4] Mialon G, Fourrier C, Wolf T, et al. GAIA: a benchmark for General AI Assistants. International Conference on Learning Representations, 2024.
北京通用人工智能研究院
