
计算机视觉与模式识别会议(CVPR 2025)作为全球计算机视觉与人工智能领域最具影响力的顶级学术会议,将于2025年6月11日至15日在美国田纳西州纳什维尔召开。北京通用人工智能研究院(简称“通研院”)联合斯坦福大学、北京大学、DeepMind、马普所、Amazon等机构,共同举办的第五届三维场景理解研讨会(5th Workshop on 3D Scene Understanding)将于6月11日上午召开,会议聚焦视觉、图形学与机器人学的交叉领域,深入探索下一代AI系统与三维环境交互中面临的核心挑战。

简介 通用人工智能的核心目标是赋予系统类人化的环境交互能力,实现复杂任务的自主规划与执行,而三维场景理解是其不可或缺的底层支撑。为实现智能系统与物理环境的深度交互,完成具有挑战性的具身任务这一目标,来自计算机视觉、计算机图形学、机器人学等不同领域的研究者们在多个方向开展了探索,并在诸多关键技术上取得突破性进展,包括:不同三维表征的优势与适用场景(如NeRF、Gaussian Splatting)、数据与模型的规模化,基于大规模数据(如:LAION-5B、Objaverse(XL)、Open X-Embodiment)训练的基础模型(如SAM(2)、Stable (Video) Diffusion),以及端到端的视觉-语言-动作(VLA)模型(如RT-X)等。

然而,当前研究面临着新的基础性问题:如何建立对环境的系统性认知框架?如何整合不同领域的创新成果,推动下一代AI的持续发展?这些核心议题又进一步引发了深度思考:
(1)传统场景解析/检测/定位,在当今发展中扮演何种角色?
(2)如何通过场景理解技术优化物理交互?
(3)纯粹端到端模型与大规模数据集的扩展能否奏效?抑或中间表征,甚至符号表征,在某些任务中更具优势?
”
自2019年起,3D场景理解研讨会(3D Scene Understanding Workshop)已举办四届(2019、2020、2021、2023年),围绕“3D场景理解”这一核心主题,聚焦计算机视觉、图形学与机器人学的交叉领域。从早期的“数据集构建”“3D表示学习”“跨模态重建”(2019-2021年),逐步深化至“物理推理与交互建模”“多任务通用模型”(2023年)。通过邀请计算机视觉、机器人学、认知科学等领域学者,持续打破学科壁垒,推动“视觉-图形-机器人”的深度融合,呼应AI技术从感知到认知的演进需求。
具体发展脉络如下:

2019年
2019年(Long Beach):首届线下CVPR Workshop,以“3D场景解析、重建与交互”为核心,邀请Marc Pollefeys、Jitendra Malik等知名学者,首次搭建跨学科交流平台。
2020-2021年
2020-2021年(虚拟):受疫情影响转为线上会议,延续基础议题并拓展至“具身任务场景理解”“神经场景表示”等方向,吸引超350人在线参与,推动虚拟协作与全球参与。
2023年
2023年(Vancouver):恢复混合形式,新增“多模态情境问答竞赛(SQA3D)”,聚焦具身智能与场景交互,首次发布Objaverse XL数据集,强化工业界与学术界联动。
本次研讨会@CVPR2025将聚焦“智能体与三维场景深度交互的基础技术探索”这一主题,重点讨论人工智能在新时代下增强交互能力的关键要素,突破具身智能的交互瓶颈,研究三维场景的物理属性建模,提升智能体与物体的交互成功率。通过特邀报告,研讨会旨在凝聚学界共识,激发创新理念,并推动在未来2至5年具有突破性潜力的研究进展。
技术挑战赛
为推进三维场景多模态理解与推理的前沿探索,本届研讨会设立三大技术挑战赛,聚焦具身智能核心能力的评测与突破。
Track1: 情境问答挑战(Situated QA,SQA)
任务目标: 在给定三维场景及智能体情境描述(如位置、视角等)的前提下,回答与场景动态交互相关的复杂问题。任务允许使用场景真实坐标信息,考察模型对空间语义与情境逻辑的联合推理能力。
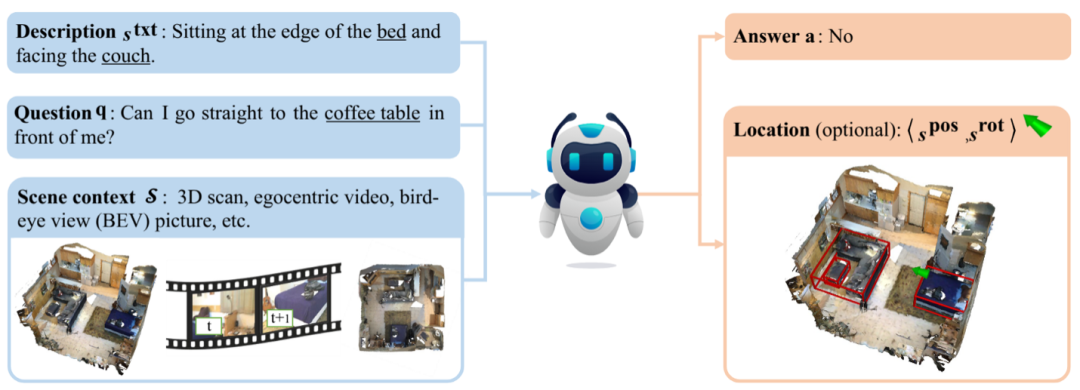
Track2: 多模态情境问答挑战(Multi-modal Situated QA,MSQA)
任务目标: 通过交错融合的文本、图像与点云数据,理解智能体所处情境。回答需综合细粒度物体属性(如材质、功能)、空间关系(如方位、拓扑),以及场景动态感知等复杂问题,以此评测多模态融合与跨模态推理的极限。

Track3: 层次化视觉定位挑战(Hierarchical Visual Grounding,HVG)
任务目标: 从区域级到物体级、从单目标到跨目标关系的逐层递进,根据自然语言描述在三维场景中精确定位目标物体。任务覆盖空间布局解析、属性关联推理及复杂关系建模能力,考验模型对场景层次化的理解极限。

参赛对象:诚邀相关领域的研究人员以及工业界技术团队参与挑战,共同推动三维场景理解,探索具身智能的技术边界!
演讲嘉宾
本次研讨会汇聚全球顶尖学者,特邀嘉宾包括:Deva Ramanan(CMU),Angel X. Chang(SFU),Daniel Cremers(TUM),Carl Vondrick(Columbia),Iro Armeni(Stanford),Kiana Ehsani(Vercept),Guanya Shi(CMU)

组织团队

挑战赛组织团队:

资深顾问:

了解更多信息及挑战赛详情,请访问:
https://scene-understanding.com/


北京通用人工智能研究院