
如果给 AI 一份
价值 100 万美元的专家工作
它今天能完成多少?
答案是:接近一半
北京通用人工智能研究院
TongAgents 团队
发布行业智能体评测基准
$OneMillion-Bench(百万美金基准)
覆盖金融、法律、医疗
自然科学与工业五大领域
这项基准第一次把
人类专家的时间与成本
作为统一标尺
直接衡量一件事:
AI 在真实行业场景中
究竟能稳定交付多少经济价值?
目前,$OneMillion-Bench 已纳入
TongTest 评测体系
为智能体时代
提供一把真正面向产业的
“价值度量尺”
资源链接: 技术报告:https://arxiv.org/pdf/2603.07980 TongAgents官网:https://tongagents.mybigai.ac.cn/
从 “答题机” 到 “生产力”:为什么行业需要一把新标尺? 随着智能体技术进入 “落地元年”,AI 正从传统的问答与内容生成,迈向承担复杂工作流的 “数字员工”。然而,业界长期缺乏能够有效衡量智能体在实际业务中创造经济价值能力的评测体系。现有基准多聚焦于知识点考查的封闭任务,在区分度、自动化评测、尤其是真实业务场景的还原度上存在局限。
为此,TongAgents 团队依托通研院在通用人工智能基础理论与认知架构方面的长期积累,致力于推动 AI迈向“认知智能” 与 “决策智能”。$OneMillion-Bench 正是这一理念在产业实践中的关键延伸:我们不仅关注模型 “知道什么”,更关注它能否在真实、开放、高价值的专业任务中,像人类专家一样规划、推理、决策并交付可落地的成果。
百万美金价值从何而来?构建真实世界的价值度量衡 $OneMillion-Bench 的核心设计理念直白而深刻:用货币度量智能体的经济价值。
通研院联合 100 余位资深专家,历时超 2,000 小时,共同构建了覆盖金融、法律、医疗、自然科学和工业五大核心领域的共计 400 道高难度开放任务。每道题背后都对应一个真实的专家级工作场景。
每个任务的经济价值,由完成该任务所需的专家耗时与权威市场时薪共同决定(时薪数据来源于中美官方统计及最新行业报告)。所有任务的总经济价值累计超过 100 万美元。这意味着,在现实世界中完成这套题目,需要支付百万美元级别的专家费用。而 AI 的表现,将直接以它 “能赚取多少美元” 来直观呈现。
图1:$OneMillion-Bench 5个领域 37个二级和92个三级细分类别
四大关键设计:真实行业场景 + 高价值任务 + 非对称负分机制 + 高质量与一致性
1、高真实性、高价值任务设计:测评题目收集自 5-15 年经验从业者的真实工作流,每道题被拆解为 15-35 个细粒度考点(累计超 7000 个考点),重点考核在特定场景下的专家级决策与实操能力,而非泛泛的知识点记忆。
2、引入 “非对称负分机制”,严防 “表面正确”:为避免 AI 通过堆砌内容 “骗取” 高分,我们首创了包含扣分项的评测方案。重大错误或逻辑缺陷将受到更重的惩罚(例如:-20 分),扣分机制的引入更符合人类在现实工作中「做对是本职,做错代价高」的职业准则,从而能引导模型追求扎实、严谨和可靠的输出。
3、深度融合国内外行业场景,精准衡量地域化能力:百万美金基准包含独立的中文(CN)与英文(Global)子集,覆盖 92 个三级行业分类,严格还原本地法规、流程与业务语境。
4、源自专家级工业化生产 Pipeline,保障数据质量与一致性:我们建立了严格的专家选拔(通过率 高难度与高保真度。
核心发现:AI 已能创造可观价值,但 “可靠交付” 仍是下一站 基于 $OneMillion-Bench 评测结果,我们获得了对当前 AI 智能体能力边界清晰洞察:
1、价值创造能力显著:当前顶尖模型在此基准上可产出约 48 万美元的经济价值,而完成这些任务的模型调用 API 成本仅约 200 美元。这证明 AI 在极高单价的专业任务上已具备强大的价值创造潜力。
2、“通过率” 揭示交付鸿沟:尽管头部模型平均分已 “及格”(>60%),但当我们以更严格的通过率(单题得分 ≥70% 视为可交付) 衡量时,即便是最佳模型,也仅能稳定交付约 45% 的任务。这清晰地表明,AI 虽已能 “帮忙”,但距离完全 “可托付” 以独立完成完整、复杂的工作流,仍有差距。
3、复杂推理与细节深挖是共性瓶颈:模型在需要多步深度演绎、探索式求解或提供极致可操作细节的任务中,仍容易出现逻辑跳步或泛泛而谈。这正是未来智能体技术,特别是像 TongAgents 这样致力于提升智能体可解释、可信决策能力的研究方向需要攻克的核心。 图2:$OneMillion-Bench模型表现和其获取的经济价值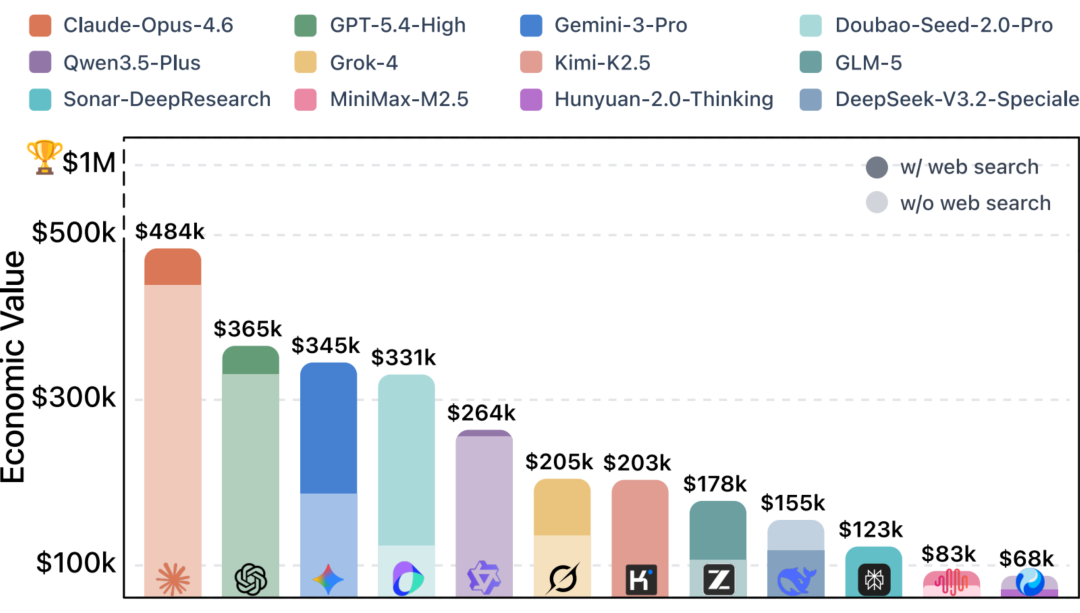
图3:智能体经济价值和开销的帕累托最优曲线 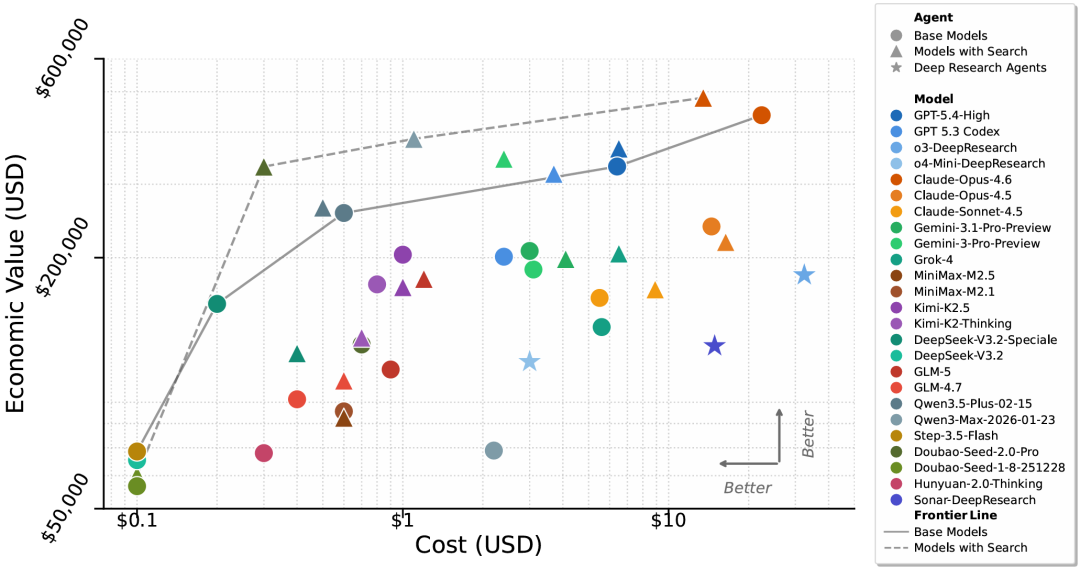
TongAgents 使命与未来:迈向 “可交付的人工智能” $OneMillion-Bench 不仅仅是一个排行榜,它是前沿基础研究与重大产业需求相结合的一次重要实践。它为行业智能体框架开发和优化提供了明确的方向与严苛的试金石,未来行业智能体将持续聚焦于: // 1、深层推理与规划能力的提升,让智能体不仅能 “答对”,更能 “想透”。 2、复杂场景的可靠落地,确保在真实、动态的业务环境中输出高确定性的结果。 3、人机协作的流畅体验,让智能体成为人类专家可信、可用、可协同的 “专业伙伴”。
站在智能体技术爆发的临界点,我们邀请学术界与产业界的同仁共同关注、使用并完善这一基准。让我们共同推动 AI 智能体跨越从 “演示效果” 到 “稳定交付” 的关键一步,让智能的每一分进步,都切实转化为推动行业发展的生产力。
关于我们
TongAgents 是北京通用人工智能研究院自研的智能体框架,支持任务规划、工具调用、学习推理和多智能体协同调度能力,提供一整套智能体全生命周期的标准化工具链,覆盖智能体的设计、训练、调试到最后的实际部署全流程。平台支持多种形态智能体的构建与发布,大幅降低使用门槛,满足不同研发能力和背景的开发者及企业的智能体构建需求。TongAgents 深度融合通院价值对齐、神经-符号-逻辑融合的算法架构,构建可信、可解释、可演进智能体。TongAgents 已在代码生成、多轮交互对话、网页深度检索等备受关注的通用智能体评测基准上取得了领先成绩,充分证明了框架在复杂任务场景下的强大泛化能力与通用性。面向政府与企业客户, TongAgents 平台已深度赋能法律、金融、教育、能源、交通等关键领域,在实际业务场景中显著实现降本增效,取得了卓越的应用成效,助力智能体技术从“可用”走向“可靠”。
”


北京通用人工智能研究院