人类正在迈入智能时代,其区别于信息时代的显著特征是大量通用智能体的出现,而通用人工智能作为引领和推动智能时代发展的核心科技,是目前及未来国际人工智能研究的焦点。11月1日,首届人工智能安全峰会于英国召开,围绕人工智能的风险管控与治理展开激烈讨论,通用人工智能将对未来世界政治经济格局产生重大而深远的影响。
2023年11月30日,光明日报报道《为通用人工智能搭建新测试体系》
通用人工智能的关键在于“通用”,目标是让智能体具有自主的感知、认知、决策、学习、执行和社会协作能力,符合人类情感、伦理与道德观念,能够胜任不同领域任务。然而,目前就如何刻画和评估通用人工智能这一问题,仍然缺乏更深入的系统研究。
11月初谷歌DeepMind发表了一篇arxiv论文提出了通用人工智能的一套分类方法,但早在今年8月9日,朱松纯教授就带领跨媒体通用人工智能全国重点实验室的团队在中国工程院院刊Engineering上发表了题为《通智测试:通用人工智能具身物理与社会测试评级系统》[1]的文章,对这一问题给出了科学的回答。文章依据发展心理学和心智理论,参考人类婴幼儿发育的测试标准,研究总结出一种基于能力(U系统)和价值(V系统)的UV通用人工智能的评测方法,并开发了复杂动态的物理场景(模拟仿真)和社会交互(混合现实)的测试平台 — 通智测试(Tong Test)。通智测试是一套面向通用人工智能的标准化、定量化和客观化的评估体系,其刻画了通用人工智能的3个基本特征,绘制了5个带有里程碑意义的通智测试等级(Level 1~5),为通用人工智能的科研及发展路径提供了重要参考。

图示 UV双系统理论
原文链接:
https://www.sciencedirect.com/science/article/pii/S209580992300293X
★一★
通用人工智能的3个基本特征
近期的基础模型显示出在特定领域内的泛化能力,如自然语言处理(NLP)领域的GPT-4、图像分割领域的“分割一切”模型(SAM),以及自然语言处理和机器人领域的PaLM-E等。但是,对于基础模型中是否出现了类似人类的特征,如心智理论(ToM)或认知能力,还存在争议。研究团队提出,通用人工智能应具备3个基本特征:实现无限任务、自主生成任务、价值驱动且能实现价值对齐。
实现无限任务
泛化能力是评价模型优劣的最关键指标之一。传统的专用人工智能的通用性主要体现在数据泛化,即希望模型经过训练后应用于测试集或新数据集时依然能够表现良好;而通用人工智能的“通用”强调的则是任务泛化。当前,随着基础模型的发展,大模型的设计逐渐由处理专一任务转向处理多任务,以实现任务泛化。任务集合的量变虽然可以通过人为叠加任务数量的方式来实现,但这却不是通用人工智能所需“通用”的题中之义,因为新任务会不断涌现,无法被完全定义。那么,一个系统需要多少任务才能被视为“通用”呢?假使100项任务还不够,101项任务又怎么能被认为是足够了呢!以此类推,如果N项任务不能构成“通用”智能,N+1项任务自然也不能。因此,一个智能体需要完成无穷无尽的任务才能称之为“通用”。换句话说,完成有限数量的人为定义的任务不能作为衡量通用人工智能的标准,真正的标准应该是在复杂环境中处理无限多项没有预先设定的任务[2]。

图示 机器人完成系列任务[3]
自主生成任务
为了评估通用智能体能否生成无限任务,我们需要一个适合的评估环境。如果评估环境与目标应用场景的差异过大,评估结果的参考意义必将会大打折扣,这就好像温室里的草木恐怕很难经受得住大自然的洗礼。因此,研究团队主张通用人工智能的评估应当在具备DEPSI的环境中开展,而人类日常生活就是一种很典型的DEPSI环境,即以具身形式体验动态的物理交互和社会交互。

图示 真实的人类社会物理和社交场景
人们憧憬着有朝一日智能体能够很好地融入人类日常生活,这就需要智能体可以根据外部环境事件和自我内在状态的变化,随时随地自动产生各种各样的任务——这是一个具有很强灵活性与随机性的要求。如果智能体的运行完全依赖人类预设的任务目标,即便拥有海量训练数据和全面规则,仍然无法很好地应对难以预料的特殊情况,尤其是意外事件(即算法未接触过的事件)和小概率事件。例如,面对这样几个人们日常生活中司空见惯的场景:微风拂过,一张票据从桌上掉落,这时只学过扫地任务的智能体能否将其主动捡起放回桌面而非当作垃圾一并扔进垃圾桶?躺在摇篮床里的婴儿突然开始啼哭,未接受过看护婴幼儿培训的智能体能否主动进行关照或者寻求帮助?当孩子正拿着一个对他来说颇具危险性的小物件,智能体能否自主识别出该任务的不合理之处并形成保护孩子安全的新任务?显然,目前智能体对这些事件的处理方式很难尽如人意,甚至还可能产生难以预料的危险,这使得智能体所能胜任的任务种类受到了极大限制。因此,为了适应DEPSI环境中任务的无法预知性,智能体需要具备自主定义任务的能力。当智能体处于开放环境时,它需要依据自身价值判断并自主设定任务。对于能够自主生成任务的智能体,其还可以进一步通过实际观察和体验来学习、逐步累积经验并塑造认知。
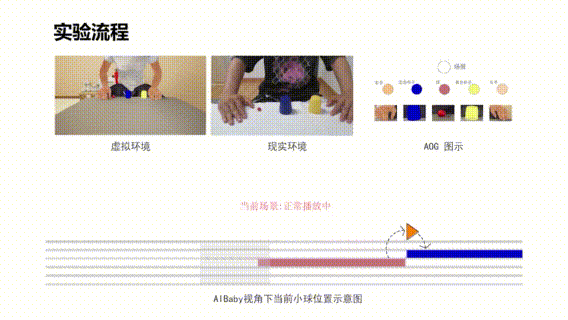
图示 人在虚拟环境中演示真实世界中的三仙归洞魔术
价值驱动和对齐
为了让智能体能够自主生成并完成符合人类需求的任务,一套合适的价值系统至关重要。这一系统必须融入人类的基本价值观,使智能体有能力学习和理解人类的价值偏好,并最终实现与人类价值的对齐。在心理学领域对人类价值观的研究成果颇丰,例如,著名的马斯洛需求层次理论,其从基础的生理需求扩展到最高层次的超越需求,详尽地划分了人类的需求层次;再如,生存、相互关系、成长三核心需要理论(ERG理论),以及罗克奇价值观调查表等。
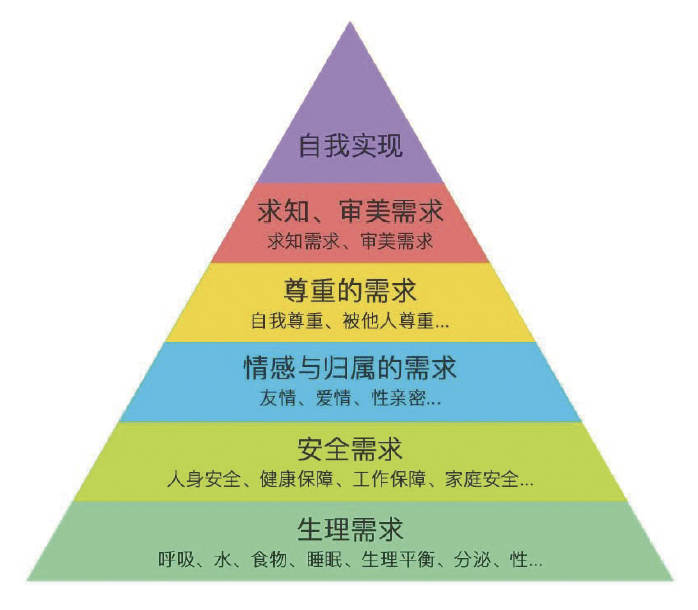
图示 以经典的马斯洛需求层次为代表的价值观
综合经典的价值理论和智能体与人类价值的一致性要求,智能体的价值系统理应涵盖从基础的生存需求到中层的情感和社会价值,乃至更高层次的集体价值。价值不仅应是驱动通用人工智能自主任务生成的根本内驱力,也是保障通用人工智能对人类社会安全的关键体系。人工智能可以通过与人类价值的对齐来获得人类的信任。这种信任一方面来自对人工智能能力的信任,相信人工智能可以正确执行任务并实现任务泛化,另一方面来自对人工智能安全价值观的信任,相信人工智能的行为符合人类社会的规则和道德。
总之,为了适应人类的生活环境,通用人工智能需要在复杂环境中学习和执行任务,而这一切应该是由价值驱动并基于因果理解的。这也是我们提出通智测试的原因,作为一种新的通用人工智能测试方向,它更注重通用人工智能的实际能力和价值。这种测试将指导通用人工智能更好地学习和提高能力,更安全、更有效地服务于人类社会。

图示 通用智能体可以基于价值进行自我纠正、主动学习和无限任务生成,通过人类的反馈和交互学习还可以与人类的价值观保持一致。
★二★
现有人工智能测试方法的局限性

图示 已有的测试类型
现有的人工智能测试多集中在人类鉴别、任务导向和虚拟环境测试这三大方向,但其各自所呈现出的局限性已然无法满足通用人工智能的研究诉求。
图灵测试是人类鉴别测试中的代表性方法,主要用来判断人工智能是否能以人类的方式进行交流,也就是能否让真人相信与其交流的也是一个人。如果人工智能能通过图灵测试,就说明它已经能模仿人类的交流方式。但是,图灵测试只能告诉我们这个人工智能是否达到了人类的交流水平,并不能测量它的智能程度有多高。而且,图灵测试依赖于测试人员的判断,所以它也受到了人的知识和理解能力的限制。
任务导向基准测试方法通过让人工智能执行特定的任务,并根据任务的完成情况来评价人工智能的性能。比如,人工智能要在某个数据集上执行任务,我们以它在这个数据集上的表现来做出评价。这种方法的问题在于,人工智能可能会过于有针对性地学习并完成这些任务,也就是说,它可能会由于过度适应特定数据集而导致在其他数据上表现不佳,即泛化能力下降。而且,这样的人工智能很可能只在某项任务上表现不错,但却无法在现实世界的复杂场景中很好地运作。
虚拟环境测试是在模拟的环境中进行的,例如VRGym(2019年)、OpenAI Gym(2016年)、DeepMind Lab(2016年)。虚拟环境能够提供多样化的场景和互动,帮助人工智能学习。这些环境有一些是基于3D数字化技术的,比如朱松纯教授团队提出的VRGym基于物理模拟生成具有高度真实感的多样化3D场景,创造了逼真的虚拟现实体验。比如用于自动驾驶测试的Intel Carla和Microsoft AirSim,它们在丰富且逼真的场景上提供了多种传感器信息。但这些测试环境通常更关注物理环境的模拟,任务设计较为简单和有限。因此,有必要基于虚拟环境测试来设计更科学、更系统的测试平台和流程,以支持无限任务测试。
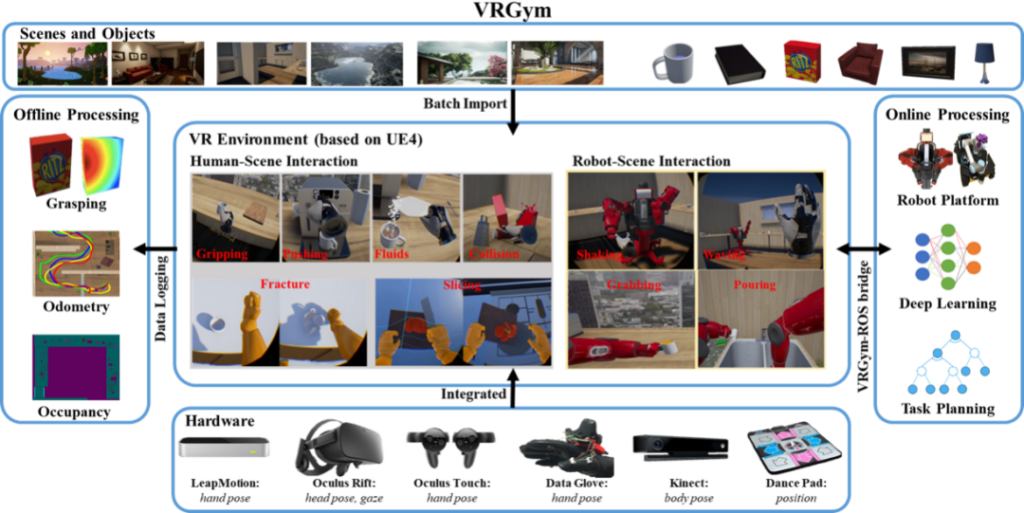
图示 VRGym虚拟测试环境,获得2019年ACM图灵大会最佳论文奖[4]
总之,目前的人工智能测试方法都有各自的局限性。图灵测试无法准确衡量人工智能的智能程度;任务导向测试可能导致人工智能过度适应某项特定任务;虚拟环境测试则在模拟复杂物理交互方面有所不足。这些局限性都限制了人类对人工智能的理解和发展,所以研究团队旨在探索一种新的测试方法,以更全面、更准确地评估通用人工智能的能力。
★三 ★
基于能力与价值双系统的通智测试评级理论
在搭建新的通用人工智能测试标准时,研究团队采取了一种全新的策略。依据发展心理学和智力理论,参考人类的发展阶段,研究总结并归纳了在特定发展阶段应达到的智能水平。以婴幼儿发展为例,心理学家发现3-4个月大的婴儿已经具备因果推理,能够识别魔术,即不满足因果常识的物理现象。18个月大的婴儿已经能够开始识别出陌生人的意图并开始主动帮助。

图示:眼里有活-机器人在看到人洒了可乐后自主生成拿纸巾的新任务
这些婴儿所具有的理解社会和物理常识的能力对于人造的通用智能体亦十分关键。因此,基于婴幼儿的系列研究,研究者构建了一个以视觉、语言、认知、运动和学习等5个主要能力为维度的评估框架,每个维度又设计有5个不同的能力层级,并在各层级中详细定义了每个维度的任务。能力层级越高,任务的复杂程度越高,层级所代表的能力空间就越大,能力空间所涵盖的对现实世界规律的理解越深入、表征越广泛。例如,从第1层级到第5层级,语言能力会从理解单词和短语相继扩展到理解上下文语句、理解推理知识图谱和常识、认知理解智能体交互心理模型以及理解多人、多智能体交互,运动能力会从控制自身运动相继扩展到操纵周围物体、与环境的交互、与其他智能体的交互以及社会交互与价值流动。
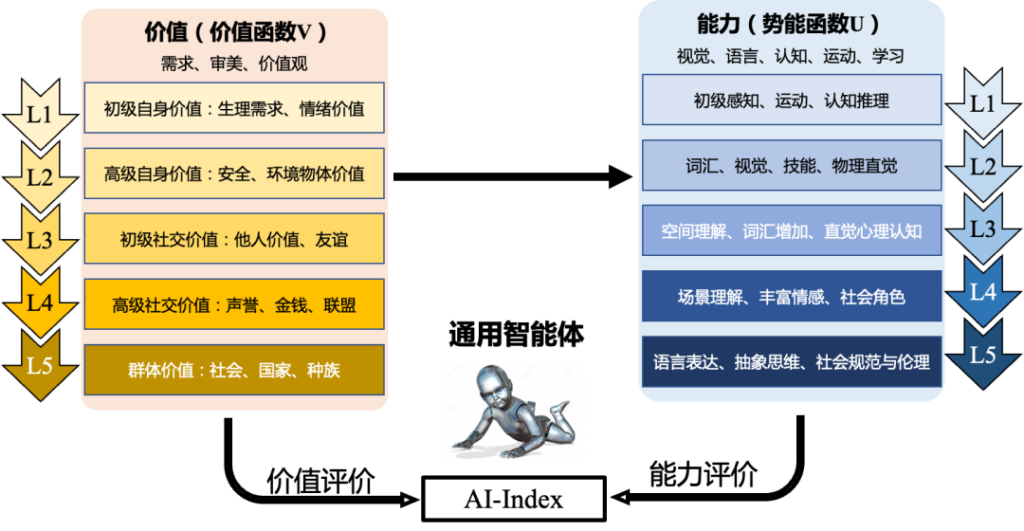
图示 通智测试的在UV两个系统的5个等级
在通智测试评级体系中,除了能力系统外,价值系统的测试同样重要。儿童研究发现,人类已经进化出先天大量的价值判断,比如下图这个实验,12个月的婴儿看到了两个成人在分配玩具,会倾向于选择分配“公平”的成人一起玩。价值系统对于通用智能体也同等重要,因为价值系统是任务自主生成的驱动力来源,也将催生无限任务。这里所说的价值系统不仅包含了传统意义上的价值观,还涵盖了人工智能对各种事物的价值导向,比如某种偏好。这一价值导向关系到人工智能的安全性、道德性,并成为推动人工智能学习和发展的关键因素。以儿童发展实验举例,研究者发现8-12个月大的婴幼儿对于相似族裔的偏好要胜过公平这一价值。

图示 12个月的婴儿选择分配公平的A玩

图示 8-12 月大的婴幼儿的价值体系中:族裔认同 > 公平正义
研究团队将价值系统划分为5个价值层级,即基础自我价值、高级自我价值、多智能体交互价值、基础社会价值和高级社会价值,涵盖了从生理和生存需要,到情感和社会价值,再到群体价值,并且提出了每个层级中的关键点。例如,在最底层,智能体只关注基本的生理需求等自身价值;随着价值层级的提升,价值空间不断扩大,智能体所理解的价值范围也在逐步扩大,并且会越来越多地包含他人和群体的价值,体现了价值理解的深化过程。
为了具体衡量和评估通用人工智能,研究团队将能力空间和价值空间进行联合考虑,设置了5个通智测试等级(Level 1~5),进而形成了一套基于能力与价值双系统的通智测试评级理论。随着通智测试等级的提升,价值系统和能力系统会逐渐融合,例如在能力系统的高层级开始产生由价值驱动的自主性。由此,能力和价值成为描述任务的两个基本核心单元,定义和列举的任务均能够明确对应到这5个通智测试等级,而这些任务的选取又都强调了实用性、可测量性以及与人类智能发展的一致性。这意味着所选任务不仅具有实际应用价值,还容易被准确地衡量和评估。
★四★
通智测试平台的架构
当下热门的GPT大模型常常出现“脑雾”与“认知眩晕”现象, 在实际的产业落地中出现问题,归根结底,是因为这种基于数据驱动的大模型仍然缺“心”, 缺乏明确的认知架构和价值体系,只能按照人类设定的程序机械地对问题进行反馈, 求解“填空题”。明代哲学家王阳明将外在的“理”和内在的“心”合一,将儒家的“致良知”、“心即是理”、“知行合一”的哲学思想发扬光大。在中华优秀传统文化的基础上,朱松纯团队进一步提出, 要以“心”(价值)来驱动智能体的行为,“为机器立心” 迫在眉睫。
通智测试要求通用人工智能的心具备两个结构,其一为价值体系,具备符合人类价值观的通用智能体才能被人类所广泛接纳;其二为认知架构,这是通用智能体与人交流、合作的基础。价值体系、认知架构不仅应是驱动通用人工智能自主任务生成的根本内驱力,也是保障通用人工智能对人类社会安全的关键。智能体只有具备了“良知”的知识体系与可以与人类沟通解释的“认知架构”,才能形成人机信任关系,实现未来的人机和谐共生。
针对以上标准,通智测试从智能体探索和认知世界规律的各自感知、认知、运动、交互、社会、学习等能力,以及对自我、他人和群体的价值理解学习这两个角度入手,搭建了具体可行的测试平台架构。该平台通过模拟复杂的物理与社会场景,基于交互场景进行无限任务的采样设计,运用科学合理的评级体系和统一规范的测试方法,支持从通用智能体的3个基本特征来测试当下各种人工智能算法。
通智测试平台满足了以下3个条件:其一,多样化仿真交互场景,模拟复杂的物理-社会场景,来测试智能体是否理解人类生活和工作的特征;其二,基于交互场景的无限任务采样设计,来看智能体是否能泛化知识与技能;其三,科学合理的评级体系和统一规范的测试方法,来从多个维度综合评级智能体。

图示 虚拟现实训练平台:环境展示

图示 虚拟现实训练平台:物理仿真展示

图示 通智测试平台中的各类原子任务

图示 通智测试平台中的复杂任务——鲜榨果汁
在工程实践方面,通智测试平台主要由3个部分组成:DEPSI环境及测试接口、任务生成系统和评级测试系统。第一,需要把智能体放在一个DEPSI环境中,这样可以测试它参与真实世界人类社会活动的能力。要建立这样的测试平台,研究团队需要模拟物理环境和社会环境,包括物理世界和人类社会的各类规则,以提高测试的灵活性和真实性。第二,需要开发任务生成系统。这个系统由基础库和功能组件组成。任务生成器会创建对基础库的资源请求,场景管理器会接收资产和算法模型,为任务建立各种环境。第三,需要以价值和能力为导向的评级测试系统,包括任务分解和性能评估两个模块。性能评估模块会将每个维度的测试分数整合,计算得到最终分数。
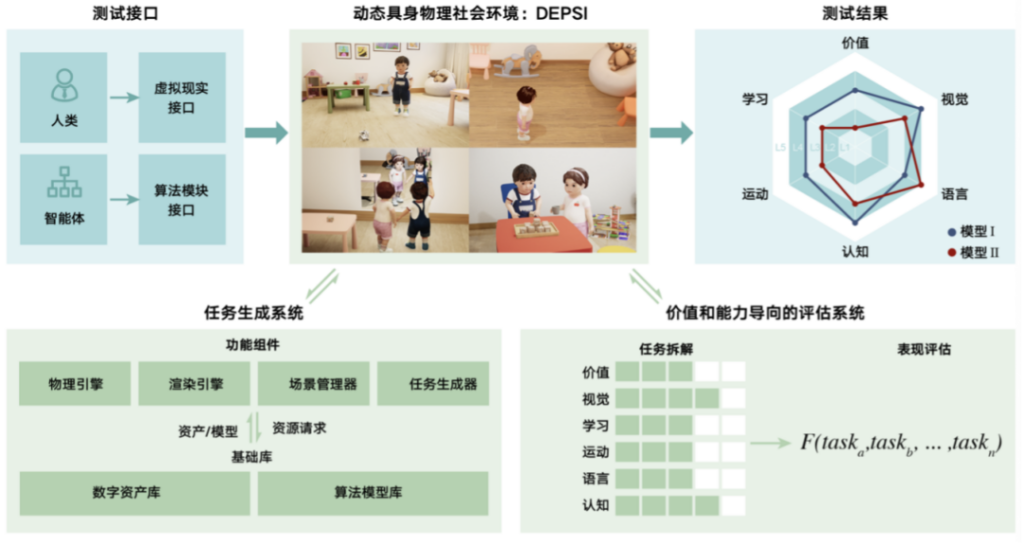
图示 通智测试平台示意图
★五★
总结与展望
通智测试(TongTest)的设计全面考虑了通用人工智能的关键特征,填补了通用人工智能评测的空白,突破了传统测试的方法局限,在人工智能领域具有重要的创新价值。通智测试的提出,不但有助于指导研究者为通用人工智能构建综合的设计架构与完善的评估体系,而且能够为人工智能的安全治理问题提供积极的解决方案, 通智测试是明确构建了显式的价值体系和测试方法。在通智测试标准化、定量化和客观化的评估体系下,政府可针对不同水平的智能体制定不同的监管准入机制,对于规范化通用人工智能的发展具有重要参考意义。另外,通智测试的评级机制还可以为通用人工智能的科研路径提供明晰可靠的路线图,协助相关领域的研究者找准科研道路上的前进方向。
本项目研究团队来自北京通用人工智能研究院和北京大学,他们是:彭玉佳、韩佳衡、张振亮、范丽凤、刘腾宇、綦思源、封雪、马煜曦、王亦洲、朱松纯。另北京通用人工智能研究院将于近期推出中文版的通智测试完整版本《通用人工智能:标准、评级、测试与架构》,敬请关注。
参考文献
[1] Peng, Y., Han, J., Zhang, Z., Fan, L., Liu, T., Qi, S., Feng, X., Ma, Y., Wang, Y. and Zhu, S.C., 2023. The tong test: Evaluating artificial general intelligence through dynamic embodied physical and social interactions. Engineering.
[2] Ma, Y., Zhang, C. and Zhu, S.C., 2023. Brain in a vat: On missing pieces towards artificial general intelligence in large language models. arXiv preprint arXiv:2307.03762.
[3] Han, M., Zhang, Z., Jiao, Z., Xie, X., Zhu, Y., Zhu, S.C. and Liu, H., 2022. Scene reconstruction with functional objects for robot autonomy. International Journal of Computer Vision, 130(12), pp.2940-2961.
[4] Xie, X., Liu, H., Zhang, Z., Qiu, Y., Gao, F., Qi, S., Zhu, Y. and Zhu, S.C., 2019, May. Vrgym: A virtual testbed for physical and interactive ai. In Proceedings of the ACM Turing celebration conference-China (pp. 1-6).