人类天生地利用多模态信息(视觉、听觉、触觉、嗅觉等)来感知和理解世界。其中,视觉和语言的多模态感知对人类而言尤为重要,且它们二者之间能起到互补和增强的作用。
比如当你在路上远远地看到一位朋友和你打招呼,他嘴里同时在说着什么,虽然你听不清楚,但也能从对方的笑脸和友好的招手姿势,大致推断出他说的是一句问候语(“嗨,Hello,好久不见……”),这就说明视觉信号可以很好地辅助语言理解。语言信号同样有助于视觉理解,比如糖和盐的外观非常相似,为了在做饭的时候快速在视觉上区分出它们,语言标签是个好帮手。
过往人们对于人工智能的技术研究大多集中于单模态领域,并在特定任务上取得了不错的性能,比如图像识别和语音识别。然而现实世界中的很多问题往往都是涉及多模态的,这就要求智能体具备和人类一样处理视觉和语言等多模态信息的能力。例如,自动驾驶汽车应该做到能够识别出交通信号和道路状况(视觉)、处理人类发出的命令(语言)。因此,多模态研究成为了近些年AI领域的研究重点,尤其是视觉-语言联合模态。
然而,当前研究人员所构建的大多数视觉-语言模型都只是在两个独立的信息流中分别处理视觉和语言信号,并仅在最后阶段把两种信号的结果进行融合,而实际,上人类对多模态信息的处理能力要机器高明很多。
例如,2020年的一项研究[i]表明,在只看得到口型而听不到声音的条件下进行唇读时,人类大脑的听觉区域可以通过接收来自视觉皮层的信号,帮助人类更好地理解唇读。还有一些行为调查、神经成像和神经解剖学等研究结果表明,在感知多模态信号时,人类的大脑中存在一个神秘的“共享世界”,充当着理解融合信息的中央处理器的角色。
受到人类大脑“共享世界”的启发,在本文要介绍的这项工作中,研究人员深入地研究了视觉-语言表示的“共享世界”,并提出了一个新的挑战——用无监督的视觉-语言语法归纳来同时提取视觉和语言的共享层次结构。本研究提出了一种名为CLIORA的新模型,该模型基于两种模态的结构化输出,在很多任务上都取得了很好的效果,并朝着对多模态信息的理解迈出了明确一步。
目前这篇工作的研究论文已被人工智能顶级学术会议ICLR 2022录取为Oral,论文一作是鲁汶大学在读博士生万博,通讯作者是北京通用人工智能研究院前沿研究中心研究员韩文娟。
论文地址:https://openreview.net/pdf?id=N0n_QyQ5lBF
一、研究启发——借鉴“对比学习”的策略
这篇论文具体做了一个什么样的研究呢?我们可以从一个“猫抓老鼠”的例子入手。
如下图所示,是一个“猫抓老鼠”的场景,用英文句子来描述这张图片,可以是“A cat is catching a mouse on grass”,也可以仅仅是“Cat catches mouse”,为了简化说明我们忽略语法问题,采用后面这个描述。

如下图所示,对人类而言,我们可以轻易地识别出红色描边区域对应着短语“Cat”,同时也对应着短语“Cat catches”,蓝色描边图像区域对应着短语“mouse”。

但是人类的这种“轻易”对机器而言却是很难的,机器要想学会这种图像区域和文本短语的对应匹配关系,则需要花费一番功夫。
如果让传统的AI模型来学习,则需要使用“有监督学习”的方式。首先要在输入环节人工对这张图片做尽可能“细粒度”的标注。所谓“细粒度”就是说要在图片中尽可能给句子“cat catches mouse”的每个短语成分都打上标签,即用若干个矩形的“边界框”把图片中的“cat”、“cat catches”和“mouse”分别框起来,并加上注释。

这种“有监督学习”的方式确实可以让AI模型取得不错的学习效果,但是通过这种方式,AI只能学到比较死板的“标签对应”关系,而不能真正学到语义理解。另外这种“细粒度”的标注数据需要大量的人工和时间成本,是一种“越人工越智能”的方法。
而本研究提出的AI模型并没有采用这种“有监督学习”方式,也不需要“细粒度”的标注数据,而是借鉴了一种无监督的“对比学习”的策略。
还是以这个“猫抓老鼠”的图片为例,如下图所示,当图片中的“老鼠”消失时,句子“Cat catches mouse”中的“mouse”也消失了,变为了“cat catches ”。这时AI就有可能会在“想”:“怎么都一起消失了?那这个mouse是不是大概对应着图片中的老鼠啊”。当然,目前的AI还远远不会思考,这里只是做一种拟人化假设。

同理,当图片中的“猫”消失时,句子“Cat catches mouse”中的“Cat catches”也消失了,只剩下了“mouse”,这时AI或许至少学到 “Cat catches”对应的是猫。

可以看出,上述的学习过程通过“对比学习”的方式,将视觉和语言结合到了一起,同时也学到了一些语义理解。这种暗含“对比学习”的策略给本文的研究带来了一些启发。当然,由于现实图片和文本信息更加复杂,本研究中实际运用的算法要远远比上述学习过程更复杂,也面临着很大的挑战。
二、提出新的任务——无监督视觉–语言语法归纳
类似上述用“对比学习”的方式学习“猫”和“老鼠”一样,本文提出了一种新的任务——无监督的视觉-语言语法归纳。在介绍这项新任务之前,我们首先提一下语法归纳的概念。
语法归纳是自然语言处理中的一项基本任务,旨在以短语结构树的形式捕获句子中的句法信息。如下图(a)所示,是英文句子“A man pushes a boy on a zip-line”的语法归纳图。可以看出,这个英文句子的主语(A man)、谓语(pushes)、宾语(a boy)、状语(on a zip-line)等不同的组成部分被短语结构树进行了归纳解析。
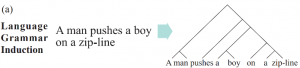
图(a):自然语言的常规语法归纳图示。
而本研究要挑战的这个新任务要做的就是——在仅仅给定输入为句子“A man pushes a boy on a zip-line”(没有给定短语)和下图图像(没有细粒度标注)的情况下,利用无监督的视觉-语言语法归纳,提取视觉和语言的共享层次结构,并给“该句子的所有短语和该图像的对应解析”的输出。

也就是想要下图这样一个结果,图中“男人”、“推”、“男孩”等区域和“A man”,“pushes”,“a boy”等短语成分产生了很好的对应解析。这其实就把语言和视觉图像给跨模态地结合在了一起,并产生了一个“对齐”。
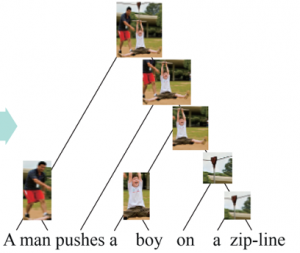
这个归纳对齐的过程叫做无监督的视觉-语言语法归纳,完整的过程如下图(b)所示。

图(b):视觉-语言语法归纳图示。
这项无监督的视觉-语言语法归纳任务其实面临着两大挑战:1、上下文有关的语义表征学习;2、分层结构所有层级的细粒度视觉-语言对齐。本研究提出的模型尝试解决这两大挑战。
三、CLIORA模型介绍
本研究提出的新模型就是Contrastive Language-Image inside-Outside Recursive Autoencoder,简称CLIORA。它借鉴了DIORA模型【2】在上下文相关的语言语法归纳方面取得的成功,并在多模态场景中进行了扩展。
CLIORA模型整个工作流程如下图所示,一共包含视觉/文本特征提取、特征级融合、结构构建、置信层融合和损失函数5个模块。整个融合过程可分为特征层(组合不同模式的特征向量)融合和置信层(组合分数)融合两步。
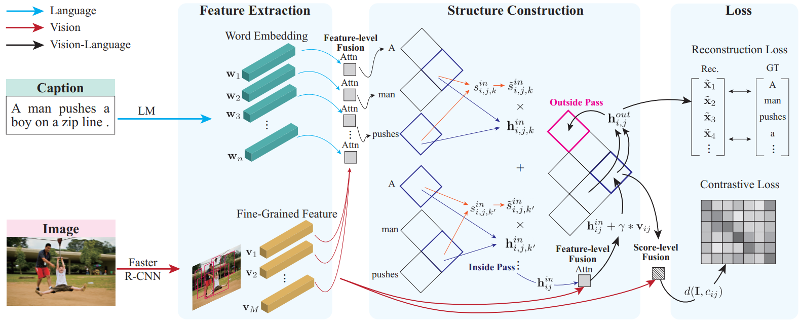
CLIORA模型示意图
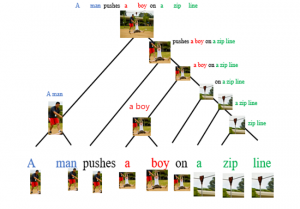
具体来说,CLIORA模型首先从视觉和语言两种模态中提取特征,然后结合inside-outside算法来计算句子成分(constituents)并构建短语句法树。在这个阶段,CLIORA模型通过递归地让语言跨度嵌入关注视觉特征,将视觉和语言这两种模态结合起来(如下图所示),这种结合过程就是特征层融合。这种融合能让文本短语关联到视觉语境,接着高效地利用视觉语境以及文本语义作为整体的语境信息,从而解决了第一个挑战。
在此基础上,研究人员计算每个组成部分和图像区域之间的匹配分数。该分数可以用于促进跨模态细粒度对应,并通过对比学习策略利用图像字幕对的监控信号。在这里,CLIORA模型通过加权跨模式匹配分数和归纳语法给出的成分分数,进一步融合了语言视觉模态,这个过程称之为置信层(score-level)融合,它确保了树结构的每一层都有细粒度的对齐,从而解决了第二个挑战。
四、实验结果
经过大量研究实验表明,CLIORA模型取得了很好的成功:
- 在新定义的无监督视觉-语言语法归纳任务上取得了很好的效果;
- 在独立的语言(语法归纳)和视觉任务上也分别取得了当前最佳的效果。
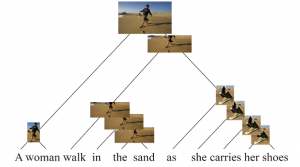
什么意思呢?首先举例来说明第一点成功。下图是利用
CLIORA模型对该图像和句子“A woman walk in the sand as she carries her shoes.”的一个无监督归纳对齐,效果很好。
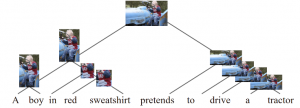
下图同样也是利用CLIORA模型对该图像和句子“A boy in red sweatshirt pretends to drive a tractor.”的一个无监督归纳对齐,效果同样很好。
通过以上两个例子以及大量未展示的其他实验数据表明,CLIORA模型确实取得了第一点成功,是在无监督的视觉-语言归纳任务取得的跨模态成功。而第二点的成功则是说,利用CLIORA模型也可以在独立的语言(语法归纳)和独立的视觉(图像-短语匹配)任务上也分别取得成功,而且要比之前这两个任务上的其他模型性能都要好。
打个比方说,这就好像有个高中生提前学懂了大学的“物理化学”课程,结果他不仅“物理化学”课学的很好,而且在高中单独的“物理”和“化学”两门课也很厉害,在考试中都取得了两门课的学校第一。
五、总结和展望
总结来说,本研究提出了有挑战性的“无监督的视觉-语言语法归纳”新任务,提出了CLIORA模型,探索了语言和图像的“共享”结构性表示。实现对语言有一个结构性表示的同时,对应图像也构建一个结构性表示,从而赋予语言和文本共享的一致性语义表示,实现统一的语言和视觉跨模态理解。
可能的未来一个研究方向是接着在视觉-语言“共享”结构性表示之外,额外定义语言和视觉各自独立的结构性表示,从而从整体上构建完整的视觉语言的“联合”理解框架,这种视觉语言联合理解框架可以显著提升AI对图片的理解,增加了可解释性。
展望未来,为视觉-语言语法归纳建模这种共享结构的最佳方法是什么?一个有希望的扩展可能是探索细粒度的视觉结构来规范共享的视觉-语言语法,本文提出的模型方法缺乏在视觉层面上的进一步探索。但是值得注意的是,视觉图像本身还包含丰富的空间结构,利用这种结构也可能有利于产生更有意义的共享结构。
回到本文研究的动机,人类如何在这样的“共享语义空间”中建模和处理多模态信息呢?本研究为语法归纳和短语落地提供了一个可能的答案。尽管如此,在人类认知计算模型中使用联结主义和符号主义表示之间的争论从未停止过。这个谜团也为人们提供了一个广阔的空间来探索建模人类多模态“共享世界”的其他潜在解释。