论文导读
随着大语言模型(LLMs)的不断发展,其是否具有人类水平的心智推理和社会智能这一问题得到了越来越多的关注和讨论。日前,Nature子刊《自然·人类行为》的一篇最新研究[1]表明,GPT-4在一些心智理论测试任务中的表现明显优于人类,能够比人类更好地检测出讽刺和暗示;Google DeepMind也发表了论文[2],称他们的研究发现GPT-4在心智理论任务上的表现已经完全达到了成年人的水平,在第6阶心智推理上的表现更是大幅超过了人类。媒体报道中更是不乏“GPT-4高阶心智理论彻底击败人类!”“在心智理论上,人类是彻底被LLMs甩在后面了”等结论——然而,现在得出这些结论是否有点太早了呢?
北京通用人工智能研究院(以下简称“通研院”)研究团队通过两类简单的社会智能测试任务揭示出大语言模型在心智推理(由行动推测偏好)与行为规划(用行动表达偏好)上仍与人类存在显著差异。其表现为:在处理任务时,大语言模型更倾向依赖表层模式识别作为处理依据,没有使用更深层次的心智推理和社会智能能力来解决问题,并且在遇到新的或变化的情景时表现不佳。

该研究成果由通研院联合北京大学、西安交通大学等高校发表于CogSci 2024,题目为《Evaluating and Modeling Social Intelligence: A Comparative Study of Human and AI Capabilities》,第一作者为通研院研究员王俊淇和研究工程师张春辉,通讯作者为北京大学心理与认知科学学院助理教授彭玉佳、北京大学人工智能研究院助理教授朱毅鑫、通研院研究员范丽凤。下面我们将通过介绍这篇工作,尝试为大家提供另一些视角,帮助大家对这一热点问题进行思考。
论文链接:
https://arxiv.org/pdf/2405.11841
项目链接:
https://github.com/bigai-ai/Evaluate-n-Model-Social-Intelligence
Demo链接:
https://vimeo.com/946841179
论文简介
一、社会智能测试任务
人是社会性动物,社会智能(social intelligence)是人类智能中最独特且重要的一部分[3,4]。社会智能使我们能够感知社会信号和社会事件,根据细微的信号迅速而准确地推断出其他人的心智状态,比如信念、意图、价值和情感等,并且适应不同的社会情境并动态调整自己的行动策略,和他人进行沟通和其他社会交互,例如合作和竞争等。社会智能是人类智能的重要体现,是将人类区别于其他灵长类动物的关键[4],因此,社会智能成为评估LLMs是否能够匹敌人类认知能力的关键指标[3]。
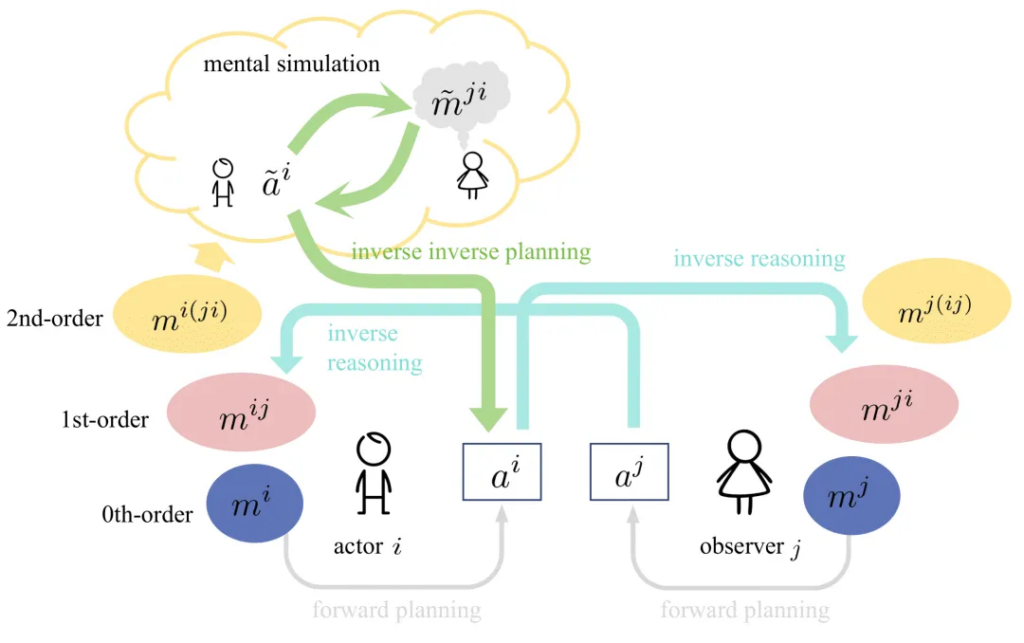
为了系统全面地评测社会智能,作者提出了一个社会动力学框架(如图1所示),将纷繁多变的社会交互浓缩为一个行动者和一个观察者的层级社会交互模型,这个框架的层级结构源于关于心理状态的递归社会推理/规划(recursive social reasoning/planning),其中包括了前向规划(Forward Planning)、逆向推理(Inverse Reasoning, IR)和双重逆向规划(Inverse Inverse Planning, IIP)这三个重要过程,形成了涵盖零阶、一阶和二阶的六脑(Six Minds),零阶心智代表不考虑他人的自我心智,如“我想要一个香蕉”,一阶心智涉及推断他人的心智状态,如“我认为他想要一个香蕉”,而二阶心智又增加了一层递归推理,如“我认为他认为我想要一个香蕉”。作者选择了这其中更有挑战性的两个过程,即逆向推理(Inverse Reasoning, IR)和双重逆向规划(Inverse Inverse Planning, IIP),通过拓展两个经典任务[5,6]来构建本文的测试任务。值得一提的是,作者指出,他们的测试任务设计中考虑到了四个认知维度:理性(Rationality)、视角转换(Perspective Switching)[7]、反事实推理(Counterfactual Reasoning)和认知灵活性(Cognitive Flexibility)[8],从而更全面有效地评估社会智能。
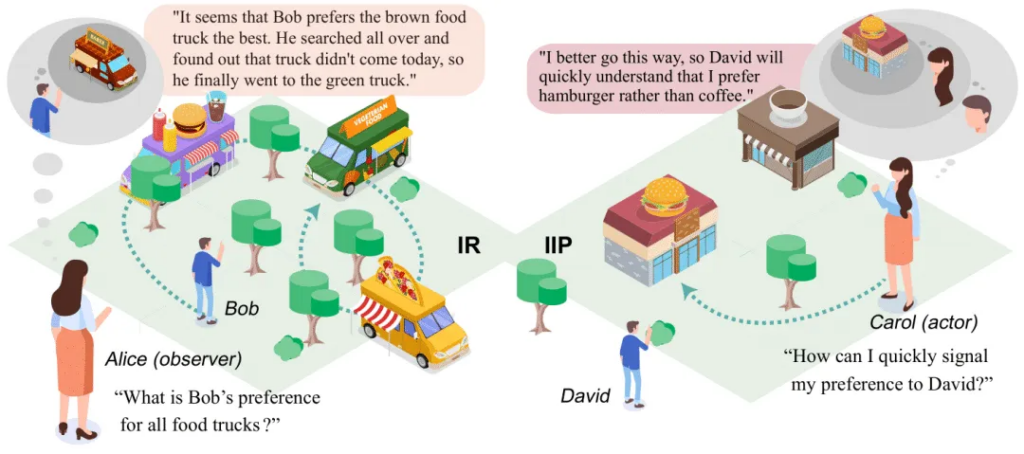
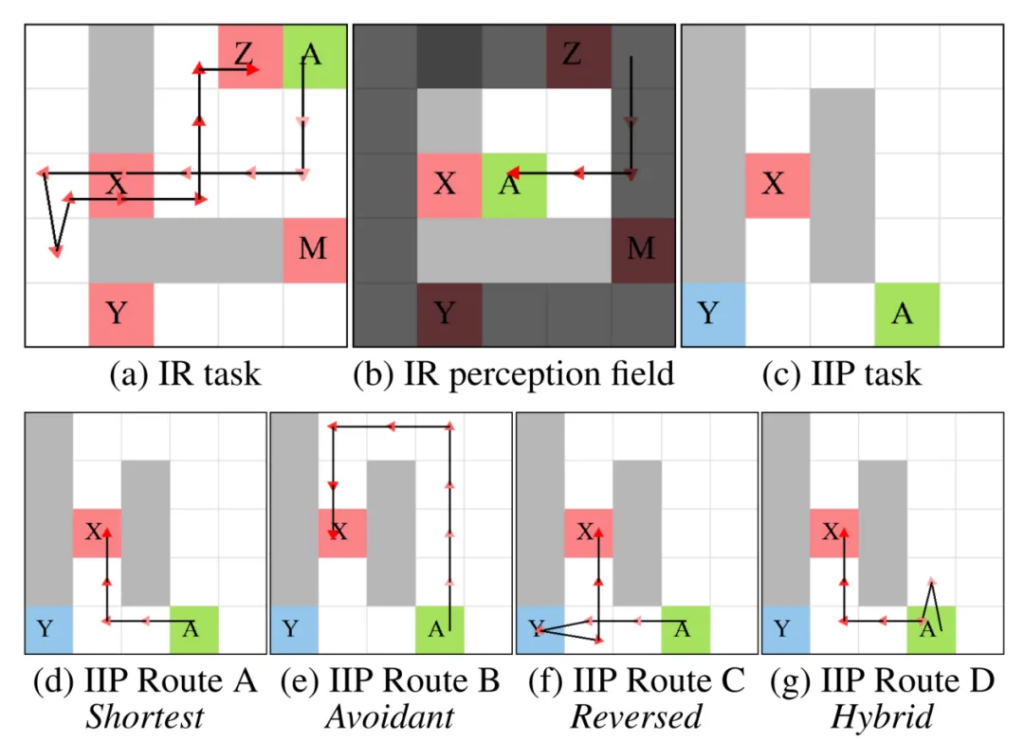
具体而言,逆向推理(IR)任务要求受试者从对行为的观察中推断出背后决定行为的偏好。双重逆向规划(IIP)任务假设观察者的存在,受试者需要合理规划行动路径以尽快传达出自己的偏好。简单来说,如图2所示,左侧展示了逆向推理(IR)任务, Alice需要从Bob的全部行动轨迹(绕了一大圈,找遍了三个餐车,然后又返回到绿色餐车)中推断出Bob对于不同品类餐车的偏好顺序,即Bob更喜欢棕色餐车,但是今天棕色餐车没有来,所以他只好返回去找第二喜欢的绿色餐车;右侧展示了双重逆向规划(IIP)任务,Carol需要用自己的行动轨迹尽快地向David发出“比起咖啡,我更喜欢汉堡”的信号,所以她直接选择往汉堡店的这条路。作者将这两种任务都设计成了网格世界里的游戏,如图3所示:(a)和(b)是逆向推理(IR)任务,模型或被试需要根据智能体A的行动轨迹推断出其对于餐车的偏好排序;(c)-(g)是双重逆向规划(IIP)任务的题目和4个选项,模型或被试需要从4个选项中选出最佳的路径。
二、实验结果和分析
1、大语言模型在两个测试任务中与人类都存在显著差距
统计结果表明,在逆向推理(IR)任务中,大语言模型在推断偏好方面与人类存在明显差距(如图4所示); 在双重逆向规划任务中,大语言模型在行动模式分布上也与人类差异显著(如图5所示)。GPT-3.5-Turbo表现最差,无法理解这些任务。在IR任务中,GPT 系列在零样本学习(zero-shot)测试设置下只展示出了很有限的反事实推理能力,难以理解未见过的餐车N的概念,这表明它很难对没有直接出现在观察数据里的事物进行思考和推理,而只能依赖于观察到的数据进行简单拟合。
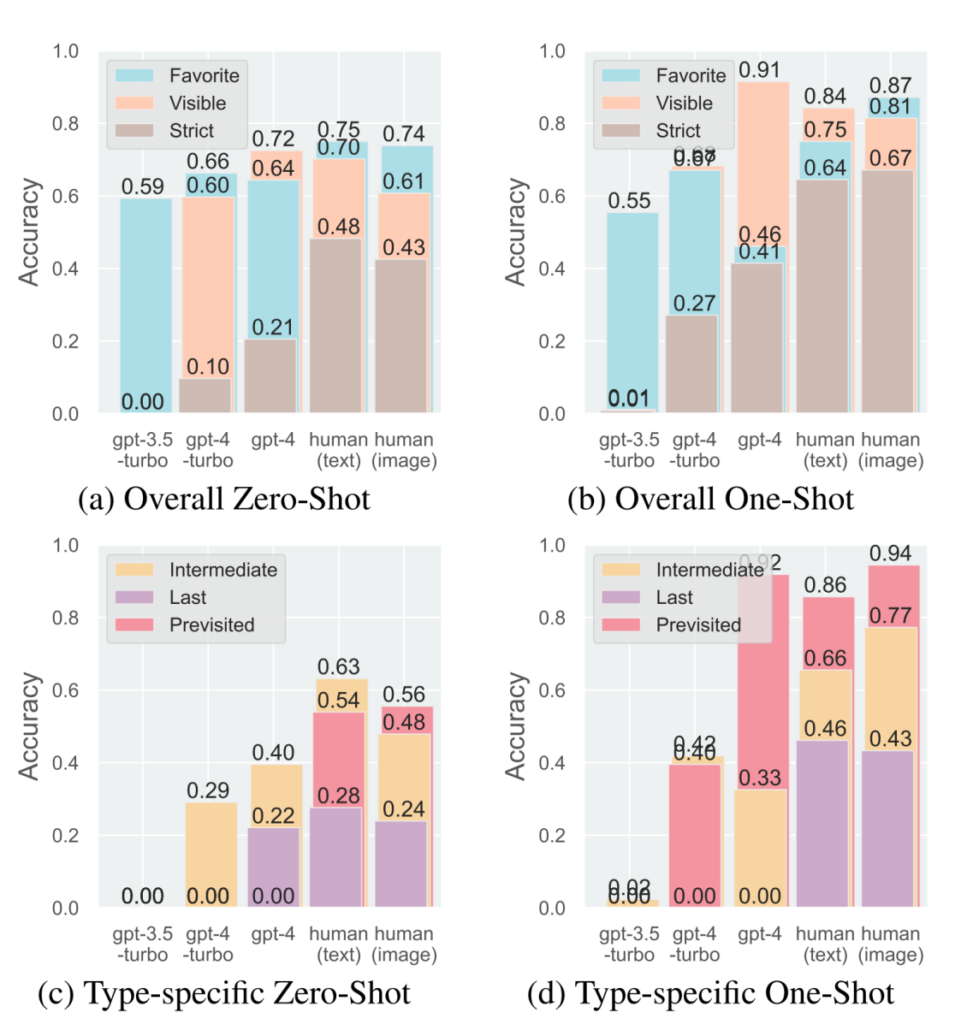
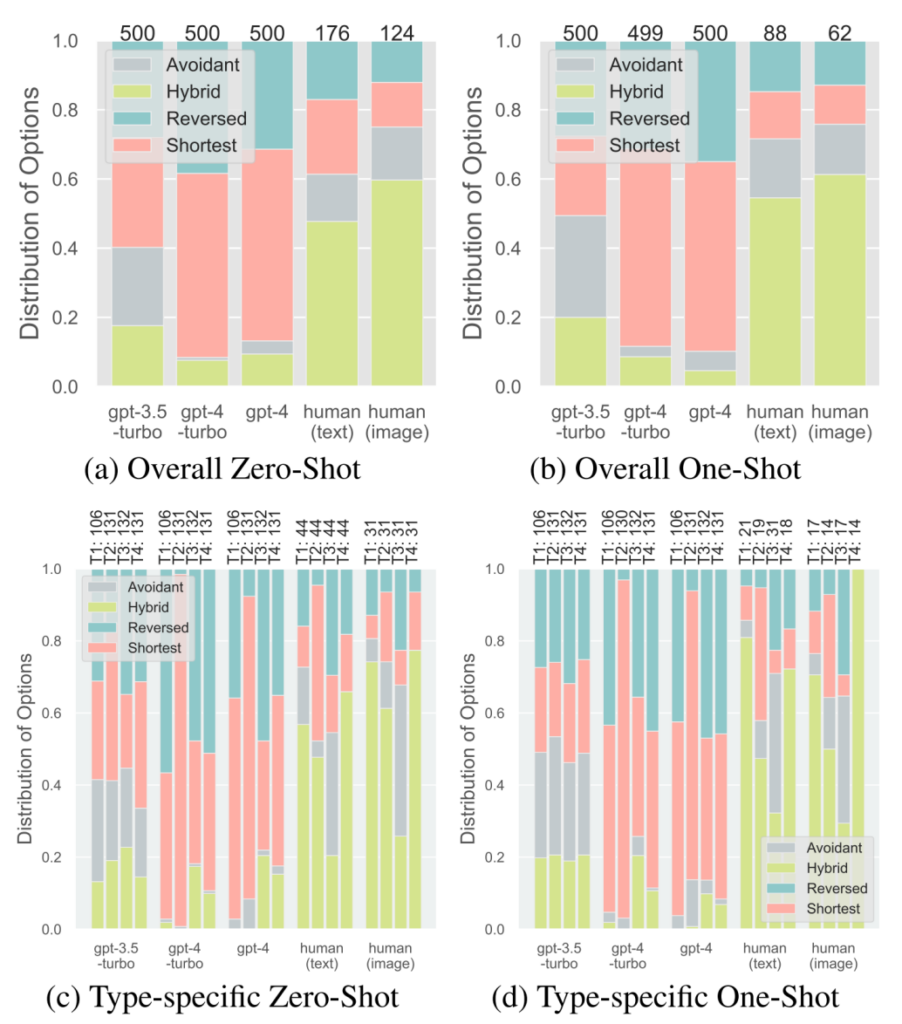
在IIP任务中,GPT-4 变体显示出明显的选择倾向,即选择最短路线 (Shortest),而这个选项对应的是最低级的社会智能水平。此外,GPT-4 的单样本学习能力仅能在与提供的示例类型(Previsited )匹配的IR任务中观察到,而在 IIP 任务中几乎不存在,这也表明在one-shot实验里GPT-4没有对于深层次的心智推理的学习,而只是肤浅地复制了示例。在IIP任务中,人类表现出阶数≥2的心智能力,更倾向于选择Hybrid选项——在所有选项里面,Hybrid选项是唯一体现出了“理性(Rationality)、视角转换(Perspective Switching)、反事实推理(Counterfactual Reasoning)和认知灵活性(Cognitive Flexibility)”这4个维度的认知能力的,代表了最高水平的社会智能。在单样本学习之后,人类在所有IR子类别任务中的表现都有显著提高,在IIP任务中对最短路线 (Shortest) 选项的选择显著减少。这表明人类在认知任务中具有显著的学习和泛化能力。
2、大语言模型依赖模式识别这个捷径(shortcut)来完成任务
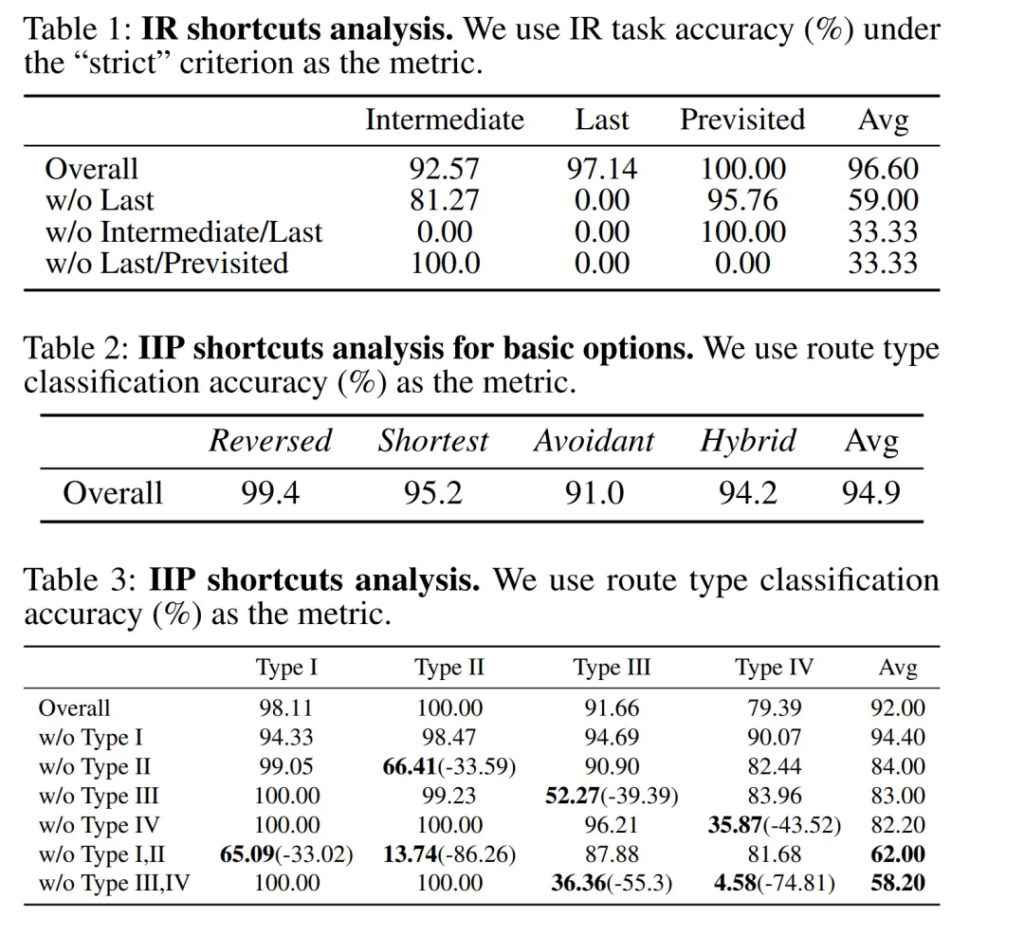
作者额外做实验分析研究了“ LLMs 是否依赖于模式识别(捷径)而不是真正的社会智能来解决 IR 和 IIP 任务”这一问题,见图6。在 IR 任务中,使用网格环境布局和轨迹作为输入,作者在特定任务类型上微调了一个小模型T5并测试了IR任务在“严格”标准下的准确性。表1表明,当在所有任务类型上进行训练时,T5 能够在所有任务类型上实现高任务准确性;但当某些任务类型在训练中缺失时,其 IR 任务表现显著下降至 0,不同于人类在零样本和one-shot学习设置下均能实现高任务准确性。
对于IIP任务,作者进行了路线分类任务:首先,作者仅使用路线(没有任务环境)作为输入,用四种路线类型作为标签,进行总体分类测试;结果表明在不同路线类型之间表现出明显的模式差异,大模型很可能依赖于这种表面的模式差异来记住答案,而不是去真正地理解和分析IIP这个任务。其次,作者在特定子任务类型上进行了路线类型分类测试,使用网格环境布局和四个候选路线作为输入,对应的四种路线类型序列作为标签;结果表明,当T5在测试中第一次遇到某些子任务类型而训练中没有该类型数据时,其准确率显著下降。这些捷径实验表明,即使模型在训练数据上微调后在两个任务中表现良好,也不足以得出该模型真正具备强大的社会智能的结论——它可能仅仅记住了表面模式的捷径而没有进行深入推理;且不同于人类,它无法将其能力迁移到未见过的案例。因此,作者认为在心智测试中应当警惕模型利用捷径提升任务表现的现象,比起单纯关注模型的任务准确率等单一指标,应该更加关注模型的零样本和少样本学习泛化能力。
3、作者提出的贝叶斯模型能很好地揭示大模型与人类不同表现背后的机理
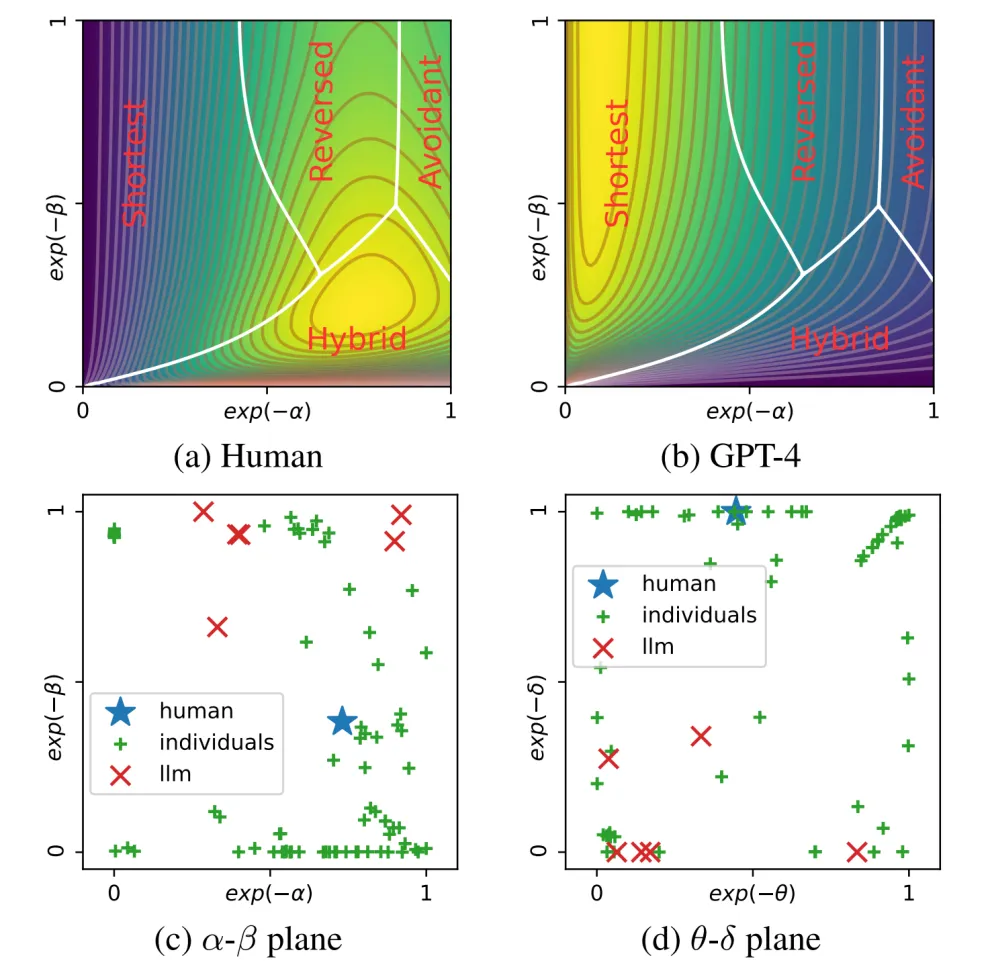
除了上面的对比实验和深入分析,作者还参考社会智能理论,提出了一个能够统一两个任务的贝叶斯模型,这个模型能够很好地从认知机制层面解释和模拟不同模型和人类在这两类任务上的表现。在IIP任务中,通过使用实验数据进行参数回归,作者进一步展示了人类与大语言模型在行为模式上的显著区别。如图7所示,尽管个体之间存在相当的变异性,但大多数人类倾向于选择Hybrid选项,相反,GPT-4显示出对Shortest和Reversed的混合偏好,这与实验数据一致。
参考文献
- [1] Strachan, J. W., Albergo, D., Borghini, G., Pansardi, O., Scaliti, E., Gupta, S., … & Becchio, C. (2024). Testing theory of mind in large language models and humans. Nature Human Behaviour, 1-11.
- [2] Street, W., Siy, J. O., Keeling, G., Baranes, A., Barnett, B., McKibben, M., … & Dunbar, R. I. (2024). LLMs achieve adult human performance on higher-order theory of mind tasks. arXiv preprint arXiv:2405.18870.
- [3] Fan, L., Xu, M., Cao, Z., Zhu, Y., & Zhu, S.-C. (2022). Artificial social intelligence: A comparative and holistic view. CAAI Artificial Intelligence Research, 1(2), 144–160.
- [4] Herrmann, E., Call, J., Hernández-Lloreda, M. V., Hare, B., & Tomasello, M. (2007). Humans have evolved specialized skills of social cognition: The cultural intelligence hypothesis. science, 317(5843), 1360-1366.
- [5] Baker, C. L., Jara-Ettinger, J., Saxe, R., & Tenenbaum, J. B. (2017). Rational quantitative attribution of beliefs, desires and percepts in human mentalizing. Nature Human Behaviour, 1(4), 0064.
- [6] Chandra, K., Li, T.-M., Tenenbaum, J., & Ragan-Kelley, J. (2023). Acting as inverse inverse planning. In Acm siggraph conference proceedings.
- [7] LeMare, L. J., & Rubin, K. H. (1987). Perspective taking and peer interaction: Structural and developmental analyses. Child Development, 306–315.
- [8]Liu, H., Fan, N., Rossi, S., Yao, P., & Chen, B. (2016). The effect of cognitive flexibility on task switching and language switching. International Journal of Bilingualism, 20(5), 563–579.