2024年
通研院实习生项目团队
研究贡献首个带语言标注的
人-场景交互动作数据集
为虚拟角色智能化交互提供关键技术支撑
研究融合自回归扩散模型与3D场景表征
攻克人体动作与物理环境自然融合难题
实现文本驱动的多阶段场景感知动作生成
该成果论文《Autonomous Character-Scene Interaction Synthesis from Text Instruction》发表于 SIGGRAPH Asia 2024
论文第一作者为通研院实习生、北京大学人工智能研究院博士生蒋楠、北大通班本科生何子默,通讯作者为朱毅鑫助理教授和通研院黄思远研究员
项目主页https://lingomotions.com/

01 概述
在计算机图形学和人工智能领域,实现虚拟人物与环境的自然交互一直是一个具有挑战性的研究课题。传统方法通常需要动画师手动设计详细的动作序列,或是依赖预设的关键帧和过渡点,这不仅耗时耗力,还难以适应复杂多变的交互场景。虽然近年来基于深度学习的方法在动作生成领域取得了显著进展,但现有模型往往需要复杂的用户输入和精确的路径规划,难以实现真正自然流畅的人物-环境互动。
人类在日常生活中展现出的交互能力为解决这一问题提供了重要启发。无论是拿起物品还是避开障碍物,我们都能自然而然地完成这些动作,而无需刻意规划每个细节。这种能力启发我们探索一种新的动作生成范式:让虚拟人物能够像真人一样,仅需简单的指令就能自主完成复杂的交互任务。
此类技术的应用前景广阔。在游戏和虚拟现实中,它可以创造更具沉浸感的交互体验;在机器人技术领域,它能够帮助机器人更好地理解和模仿人类动作;在数字人领域,它可以实现更自然的虚拟助手和数字演员。同时,这项技术还可以应用于动作分析、康复训练等领域。
为了实现这一目标,研究团队提出了一个创新的生成模型框架,该框架整合了三个关键组件:
(1)一个自回归的动作扩散模型,用于生成连续流畅的动作序列;
(2)一个双体素场景表征系统,提供全面的环境理解;
(3)一个时间-语言联合编码器,实现文本指令和时序信息的有效整合。
为了训练这个系统,研究人员构建了LINGO数据集,通过VR技术辅助收集大量真实人类与环境交互的动作捕捉数据,涵盖40多种日常交互动作。
与现有方法相比,该方法具有以下优势:首先,它能够仅通过简单的文本指令就生成复杂的多阶段动作序列;其次,它能够实时感知和适应环境变化;最后,它生成的动作更加自然流畅,更接近真实人类的行为模式。这些特点使我们的系统能够在实际应用中展现出优越的性能。

图:模型近乎实时地对输入命令做出反应,打断当前动作并丝滑地衔接到下一段动作。
02 研究方法
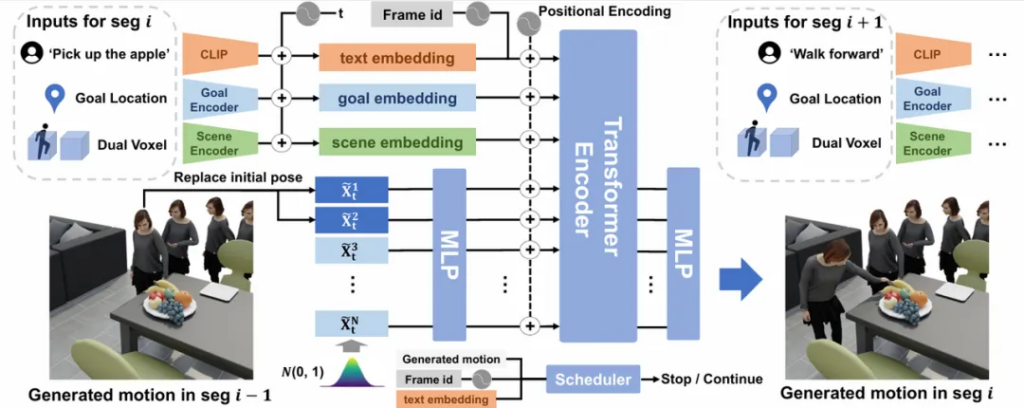
图:自回归动作扩散模型,给定先前的动作序列、三维场景信息、生成符合文本指令与目标位置的连续的下一动作序列。
动作扩散模型
本文方法的系统核心是一个自回归的动作扩散模型,这个模型的设计灵感来自于人类自然调整动作的过程。想象一下当我们走向办公桌准备拿起咖啡杯时,我们的大脑会不断处理和调整动作:首先迈步走向桌子,同时观察周围环境;当接近桌子时,我们会自然地放慢脚步、伸出手,最后精确地抓住杯子。这整个过程是连续且流畅的,每个动作都建立在前一个动作的基础之上,并为下一个动作做好准备。
本文使用扩散模型来实现人体动作的生成,可以将其理解为”从模糊到清晰”的渐进。模型从一系列随机的人体动作开始,通过逐步去噪的过程,最终生成出自然流畅的动作序列。

图:使用双体素的局部场景表征
双体素场景表征
在一个陌生的房间里行走时,我们不仅需要清楚地知道眼前的情况(比如这里有张桌子、那里有把椅子),还会自然地思考”前方的路是否通畅”、”目标物体周围有没有足够的空间”等问题。
正是基于这种人类感知环境的方式,研究中设计了双体素场景表示系统。简单来说,体素就像是三维空间中的”像素”。如果将整个3D场景分割成许多小立方体,每个小立方体就是一个体素,它们记录着空间中每个位置是否被物体占据。
第一部分体素专注于观察当前位置周围的即时环境,就像我们行走时会注意脚下和周围的情况。第二部分体素则会观察目标位置附近的环境,用于评估目标位置是否容易到达,以及目标物体周边的场景布局。
时间-语言联合编码器
本研究还使用了时间-语言联合编码器,同时编码时间和文本的信息。这个编码器将文本指令与时序信息整合在一起,意味着它不仅理解要执行哪些动作,还知道何时执行这些动作。这一整合确保生成的动作能够准确地与文本中描述的预期动作保持一致,就像人类自然地以完美的时机排序他们的动作一样。
基于VR的数据集构建
使用动作捕捉系统拍摄人与物体的交互动作,就像是在拍一部动作电影,演员需要和周围的物品互动。传统方法不仅要布置各种道具和场景,这些东西还可能挡住摄影机,影响拍摄效果。
本研究则采取了更加巧妙的办法:让演员戴上VR眼镜,在虚拟世界里”演戏”。也就是说,在构建LINGO数据集的过程中,演员看到的是虚拟场景,但他们的动作是真实的,就像打游戏一样自然。
用这个方法,研究团队轻松收集了超过16小时的动作数据,覆盖了120个不同的室内场景,记录了约40种动作类别。这些珍贵的数据就像是教计算机理解人类动作的”教科书”,帮助机器更好地把我们的语言指令转换成自然的人-物交互动作。

图:LINGO场景动作捕捉数据集样例
03 结论
本研究提出了一个人与场景物体交互动作生成的框架。该框架能够直接根据文本指令和目标位置自主合成多阶段、场景感知的人体动作。本文通过新颖的3D场景表示以及时间帧和语言的联合嵌入,将人体动作无缝接入3D场景。本研究还贡献了一个详细的、带有语言标注的动作捕捉数据集,服务于未来人体动作的相关研究。