在探索具身智能的征途中
三维视觉语义落地
一直是一道亟待攻克的难题
面对数据的复杂性和稀缺性
我们如何跨越障碍
推动三维视觉语言学习迈向新高度?
北京通用人工智能研究院推出
创新成果:SceneVerse
推动三维视觉语义落地迈向新阶段
作为首个百万级
三维视觉-语言数据集
在规模效应和零样本迁移能力上
展现出巨大潜力
该成果论文《SceneVerse:Scaling 3D Vision-Language Learning for Grounded Scene Understanding》已发表于ECCV 2024
论文共同一作为通研院通用视觉实验室研究员贾宝雄和陈以新;通讯作者:黄思远

论文地址https://arxiv.org/abs/2401.09340

研究导读
三维视觉语义落地(3D Vision-Language Grounding)作为具身智能的核心任务,因其固有的数据复杂性和稀缺性,长期面临着巨大挑战。为攻克这一难题,通研院创新性推出 SceneVerse:首个覆盖 68,000 个室内场景、拥有 250 万对高质量视觉-语言对的百万级数据集。立足SceneVerse,研究团队设计了基于多层级对比学习的三维场景-语言对齐预训练框架GPS(Grounded Pre-training for Scenes),不仅在现有三维视觉-语言任务中显著超越当前最佳模型表现,更在规模效应和零样本迁移能力上展现出与早期二维视觉-语言模型相似的潜力。通过进一步实验探索,研究人员深刻认识到三维视觉-语言数据在数据规模和语言质量等关键维度上仍存在巨大的提升空间,因此期望SceneVerse能成为迈向未来可泛化三维场景语义落地模型的第一步。
研究背景三维视觉语义落地致力于将语言与三维物理环境对齐,是构建具身智能体的基石任务。近年来,多模态大模型(Multi-modal Large Language Models, MLLMs)的发展极大地推进了二维视觉领域的视觉-语义对齐,这得益于大规模图像-语言数据集[1]的支撑。然而,将这些成功经验从二维扩展到三维面临诸多挑战:三维场景由于其多样的物体配置、丰富的属性以及复杂的空间关系,天然比二维图像蕴含更多信息,这使得语义落地更加困难。尽管三维数据采集技术在不断进步,但三维数据采集的固有复杂性和高昂成本,使得现有三维场景-语言数据在规模上与二维数据集仍有数量级差异。数据的稀缺也导致研究无法设计出一个统一学习框架来有效实现三维视觉语义落地。
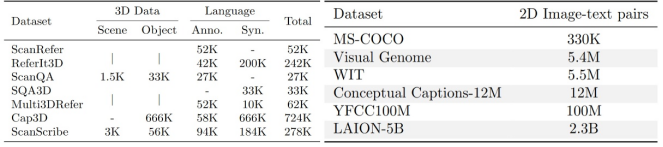
图 现有三维视觉-语言数据量(左)相比二维视觉-语言数据量(右)仍有数量级的差距为解决三维视觉-语言学习中的数据挑战,研究团队提出 SceneVerse – 首个百万级三维视觉-语言数据集。该数据集覆盖68,000个三维室内场景,借助标注以及基于场景图的数据生成方式,构建起250万对高质量视觉-语言对。基于这一大规模数据基础,研究提出三维场景-语言对齐预训练框架GPS(Grounded Pre-training for Scenes),在多种三维视觉-语言任务上达到现有模型最佳,为三维视觉-语言学习开辟了新的研究思路。
研究创新
大规模三维场景-语言对齐数据构建SceneVerse汇集了来自各种现有数据集的3D场景,涵盖真实环境和合成环境。借助3D场景图和大型语言模型的强大能力,研究团队开发了一条自动化流程,为对象级和场景级描述生成详尽且高质量语言。

图 SceneVerse涵盖的场景数据集一览为解决可用三维场景数据稀缺这一问题,研究人员汇集了五个现有大规模真实三维场景数据集(包括ScanNet、ARKitScenes、HM3D、3RScan)以及两个现有大规模仿真场景数据集(Structured3D和ProcTHOR)。为确保来自不同数据源的场景数据的统一性,对场景进行了坐标轴对齐、归一化及语义标签对齐等预处理操作,最终得到68406个三维场景,用作视觉-语言对齐研究。
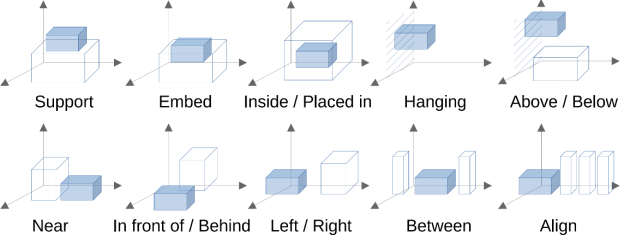
图 SceneVerse场景图构建中考虑十种位置关系可视化
基于所收集的三维场景,研究人员生成结构化的三维场景图(3D Scene Graphs)[2],以便实现语言数据的自动化生成。具体来说,场景图以物体作为节点,节点间以物体间空间位置关系的语义进行连接。研究利用规则定义了10种物体间空间关系,其类别如下:
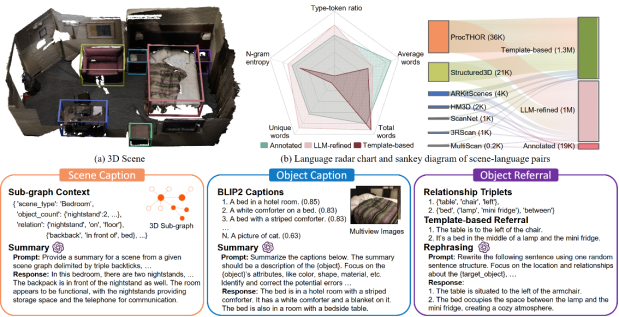
图 SceneVerse数据生成流程示例及数据统计在三维场景图的基础上,研究人员利用大语言模型自动化生成三个层次的场景描述:1.物体描述:利用物体的多视角图片及二维视觉语言模型生成的物体特征、属性描述。2.物体指代:基于关系模版通过场景中的邻居节点及关系生成语言描述指代场景中某一物体,并通过大语言模型对生成文本进行优化。3.场景描述:基于三维场景图以及物体信息生成对场景的全局描述。为避免大语言模型的幻想问题,研究人员设计提示词来减少反事实错误并通过人工反馈对提示词进行迭代。经过上述流程,最终获得约250万三维场景-语言数据对,其具体统计信息及与现有工作对比如下:
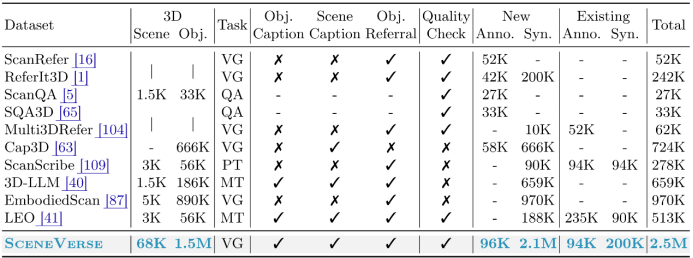
图 SceneVerse数据与现有三维场景-语言数据集在场景、语言规模及种类等多方面的对比
研究人员再次提供一些数据可视化结果,欢迎访问网站(https://scene-verse.github.io)查看更多可交互样例。
场景理解预训练模型GPS
在模型侧,研究中借鉴二维图像-视觉对齐领域常见的对比预训练(contrastive pre-training)方式[3],提出基于transformer的三维视觉-语言预训练框架GPS,期望在新的数据规模下可以通过统一的场景-语言间对比学习的形式,规避过往三维场景语义落地方法中所需的任务定制化模型设计或额外损失函数。
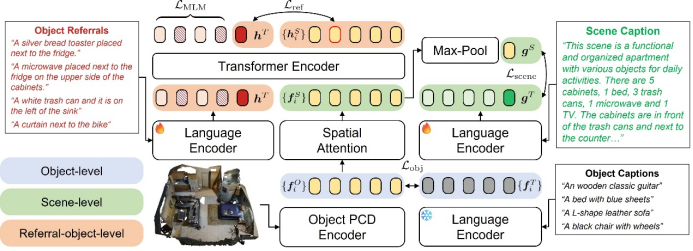
图 GPS预训练框架在物体描述、物体指代及场景描述三个层级完成对比学习
与生成的数据相对应,GPS训练框架在场景描述层、物体描述层及物体指代三个层级中通过场景-文本对比对应的形式完成学习任务。
结论与发现研究团队在广泛认可的三维场景-语义对齐测试数据集上,对SceneVerse数据和GPS预训练框架性能进行了全面评估。实验结果显示,在物体指代任务(涵盖ScanRefer、Nr3D及Sr3D数据集)和三维场景问答任务(包括ScanQA和SQA3D数据集)上,该研究方法在全部五个权威数据集上刷新了现有模型表现,体现了基于SceneVerse数据预训练的GPS模型作为通用三维语义落地骨干(Backbone)网络的潜力。
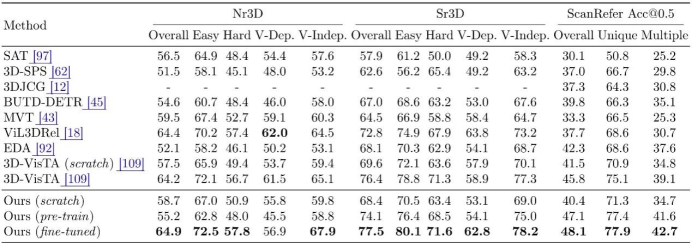
图 GPS模型在常见三维场景物体指代数据集上的评测结果
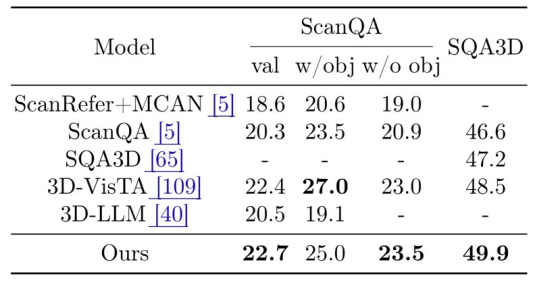
图 GPS模型在常见三维场景问答数据集上的评测结果
在此基础上,研究人员进一步对基于SceneVerse数据的GPS模型预训练规模化效应(Scaling Law)与零样本迁移(Zero-shot Transfer)泛化能力[4]展开探究。为进行这一探索,研究人员通过控制模型训练阶段可见的数据种类与规模,构建了严谨的零样本迁移评测环境。
实验发现,随着数据规模的递进,GPS模型呈现出与二维预训练模型高度一致的规模效应,并展现出较强的泛化能力。这些实验结果展现了在三维视觉-语言对齐领域中数据规模化的重要作用。
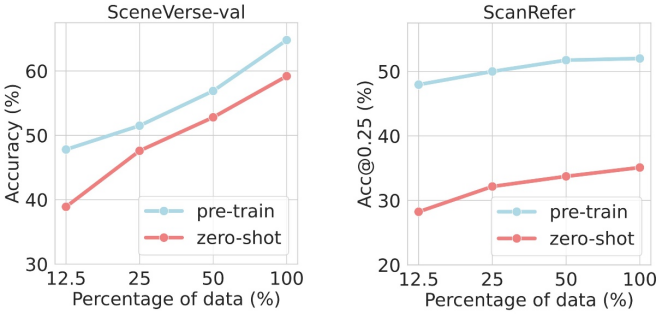
图 GPS模型在数据规模变化时的规模效应及零迁移能力验证
面临挑战
三维视觉-语言仍存在的挑战。在本次数据规模化及模型预训练过程中,也发现了一些现有数据及模型设计方面仍然面临的挑战。
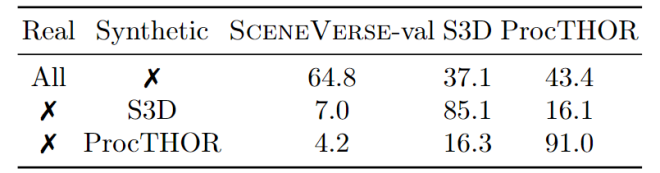
图 GPS模型在仅仿真数据上进行训练时在真实场景中泛化能力较差,展现了仿真-真实数据间巨大数据差异
该研究表明,场景数据集之间存在显著的结构性差异,涵盖物体摆放、场景规模和密度等方面。通过对真实场景和仿真场景在实验过程中的系统性比较,观察到模型在跨数据集泛化中面临严峻的性能下降。这一发现凸显出目前三维场景数据规模仍存在局限性。
尽管场景-语言数据已达到百万级规模,但三维场景数据质量和多样性与二维图像仍存在本质差距,故而目前的场景数量及多样性仍是模型泛化的瓶颈之一。为解决这一问题,仍需进一步探索可规模化获取三维场景的方法。
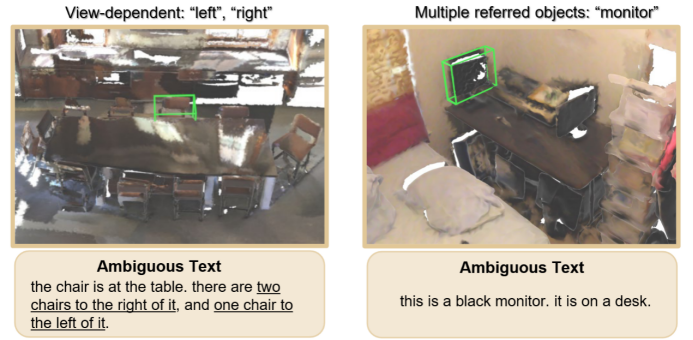
图 在现有三维场景-语言数据集中频繁出现的物体描述歧义性问题在整合现有三维场景-语言数据集进行联合训练时,研究人员发现大量的数据质量问题,尤其是物体指代中普遍存在的歧义问题。三维场景中的空间关系本质上高度依赖观测视角(如左右、前后等),这使得准确描述对象变得复杂。解决这一问题的关键在于在生成物体描述时充分考虑相对参照物及情景,研究人员希望通过SceneVerse中的数据规模化流程,为三维场景语义落地中的这些挑战提供新的研究视角和思路。
作者简介:
贾宝雄,北京通用人工智能研究院通用视觉实验室研究员,本科毕业于北京大学,博士毕业于美国加州大学洛杉矶分校,期间师从朱松纯教授并曾于Amazon Alexa AI实习,研究方向包括场景理解、行为理解、具身智能等,发表顶会论文二十余篇(CVPR,ECCV,ICV,NeurPS,ICLR,ICML,IROS)。曾组织多届国际会议研讨会、长期担任国际顶级期刊及会议审稿人,并曾获得CVPR及ICLR优秀审稿人奖。
/参考文献 /
[1] Schuhmann, C., Beaumont, R., Vencu, R., Gordon, C., Wightman, R., Cherti, M., … & Jitsev, J. (2022). Laion-5b: An open large-scale dataset for training next generation image-text models. Advances in Neural Information Processing Systems, 35, 25278-25294.
[2] Armeni, I., He, Z. Y., Gwak, J., Zamir, A. R., Fischer, M., Malik, J., & Savarese, S. (2019). 3d scene graph: A structure for unified semantics, 3d space, and camera. In Proceedings of the IEEE/CVF international conference on computer vision (pp. 5664-5673).
[3] Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., … & Sutskever, I. (2021, July). Learning transferable visual models from natural language supervision. In International conference on machine learning (pp. 8748-8763). PMLR.
[4] Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., … & Amodei, D. (2020). Language models are few-shot learners. Advances in neural information processing systems, 33, 1877-1901.