人类智能的重要标志之一是“小数据、大任务”,即从极其有限的数据中抽象出模型,归纳推理、举一反三。当前以深度学习为代表的人工智能范式则是通过统计方法从海量的数据中寻找到相关性,完成特定任务,其数据利用效率低,且算力资源消耗巨大。如何创造出像人类一样具备高效推理能力的智能体,是实现通用人工智能中的关键问题。
近期,由北京通用人工智能研究院的张驰与贾宝雄研究员、北京大学人工智能研究院的朱毅鑫助理教授和朱松纯教授组成的科研团队的一项突破性研究成果“人类水平的小样本概念学习”(Human-level few-shot concept induction through minimax entropy learning)在国际顶级学术期刊《科学 进展》上发表。该研究成果被《人民日报》以《学习“小样本”, 练出“大智慧”》为题进行报道,并指出该研究探索通用人工智能的路径,是中国科学家独立完成的人工智能领域从0到1的突破。其技术能力也应用在2024中关村论坛十项重大成果之一的通用智能人“通通”上,具有重要的意义和影响力。

学习“小样本” 练出“大智慧”
论文地址:
https://www.science.org/doi/10.1126/sciadv.adg2488
当前广泛应用的AI系统主要以海量数据为基础,利用大量算力和存储进行数据检索、融合与生成,其核心范式是深度学习,但其对大量数据和算力的依赖也导致了成本的显著增加。本研究聚焦机器模型如何通过小数据理解IQ测试中的时空因果关系,其AI系统在没有大数据训练的情况下,通过概念学习和逻辑推理的方式完成测试任务, 在智商测试中超过了高智商人群。
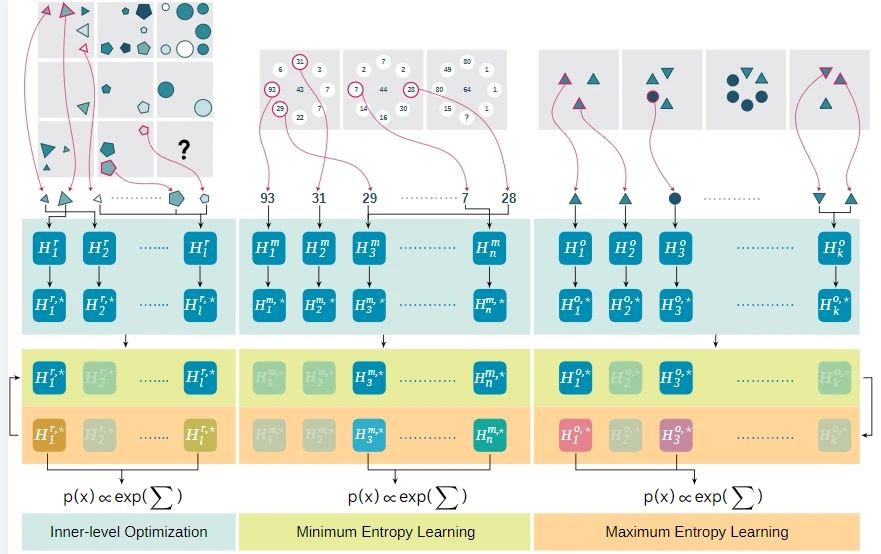
具体而言,研究团队借鉴朱松纯教授在90年代提出的最大最小熵建模原理[1],即用统计数据建模的方式找出现有少量数据间的联系,用高效率的算法来代替穷举,从而求解问题。这一方法最早应用于计算机视觉领域的图片生成模型。受此经典研究思路的启发,团队将问题形式化为易于求解的优化问题,并按照熵的思路将其描述为概率条件下的熵限制问题,使模型在快速迭代后能取得满意结果。
不同于深度学习的大数据范式,本研究采用的“小数据、大任务”范式着重强调模型即时的学习能力和学习效率,属于小样本学习的一种。如果将大模型、大数据比作“死记硬背”“题海战术”,那么小数据就是“现学现卖”。这一“小数据”学习范式的目的,就是为了给模型提供无限任务学习的可能:对于新定义的任务,大模型范式受限于其数据为基础的理论,必然不能解决全新定义的任务,或者现有数据量很小的任务,而“小数据”使得我们能够在非常少量给定的任务中,依然能取得非常有效的结果。从学习效率上说,小数据依赖,能大量节省计算的能耗,规避大模型训练中的诸多效能问题。
以教育方式为例,众所周知,填鸭式教育或题海战术是有极大弊端的,就算学生能够在重复的题型和测验中取得满意的成绩,但如果失去了举一反三的能力,那么学习的成果也是很难被应用到全新的场景中的。“小数据、大任务”的核心就是这种举一反三的能力,或者说对问题的“理解”。对问题的理解需要对实际问题进行细致的分析,在时间、空间、因果等多个层次上对问题解译、建模,然后根据构建的模型获得结论。从神经学的角度来看,这种能力对应于我们双认知系统中的第二系统(System 2)。这样的系统更加反映模型在真实世界中的能力。
朱松纯教授提出的最大最小熵模型是现在广泛使用的生成式模型的根源,其核心在于如何对概率建模,并使用马尔科夫链蒙特卡洛采样算法对于概率取样并进行模型迭代。现在的生成式模型算法,基本都是基于这套能量相关理论构建的。其差异之处,主要还是在于使用了神经网络等相关技术,但显而易见的,使用了神经网络技术的相关模型无法进行小数据上的推理,而传统的方法在改进后在少量数据上具有巨大的潜力。
在过去的几十年中,人工智能和机器学习在感知任务上取得了显著进展,这些任务通常依赖于大量、精心策划的数据集。然而,人类智能的核心——关系归纳领域——尚未得到充分解决。人类能够通过少数例子辨识并归纳未见过的关系[5,7]。本研究试图以瑞文测试为对象,通过赋予机器归纳推理的能力,来提高机器的智商,特别是在处理抽象推理任务上。
尽管人工智能在图像识别和语音处理等领域取得了巨大成功,但在关系归纳上,机器与人类之间存在显著差异。人类可以无监督地从少数示例中推断和归纳隐藏的关系概念,并利用这种理解来预测后续的结果。相比之下,现有的机器学习框架,尤其是基于深度学习的框架,通常采用监督学习的方式,尚未达到人类常展现的归纳推理水平。
在归纳效率上,人类和机器也有明显的区别,人类能够从单一的情境实例中归纳出新概念,而机器通常需要大量的成对实例进行训练。这种差异表明,机器学习方法可能将归纳简化为单纯的死记硬背,从而破坏了智力测试的根本目的。
在本研究中,团队通过最小最大熵学习实现人类水平的少量样本概念归纳的计算模型。该模型模拟了人类在抽象推理任务中的归纳推理能力,如智力测验中的问题,使用了最小最大熵方法。这种方法通过最小熵确定数据上最有效的约束,并通过最大熵确定这些约束的最佳组合。研究表明,该模型仅通过一个实例就能引导概念,达到了人类在瑞文测试(RPM)[2]、数感(MNS)[4]和异类甄别(O3)任务上的表现水平,展示了最小最大熵学习在使机器能够有效地、用最少的输入学习关系概念方面的潜力。
在我们模型中,每个实例都通过一个不同的描述性模型独立建模——即采用Gibbs形式的基于能量的表述,与之前的工作不同,我们基于最终目标采取全局优化的视角:我们最初用潜在的滤波器组成我们的能量模型,动态地修剪和添加滤波器,然后通过最小最大熵原理权衡它们的组合。
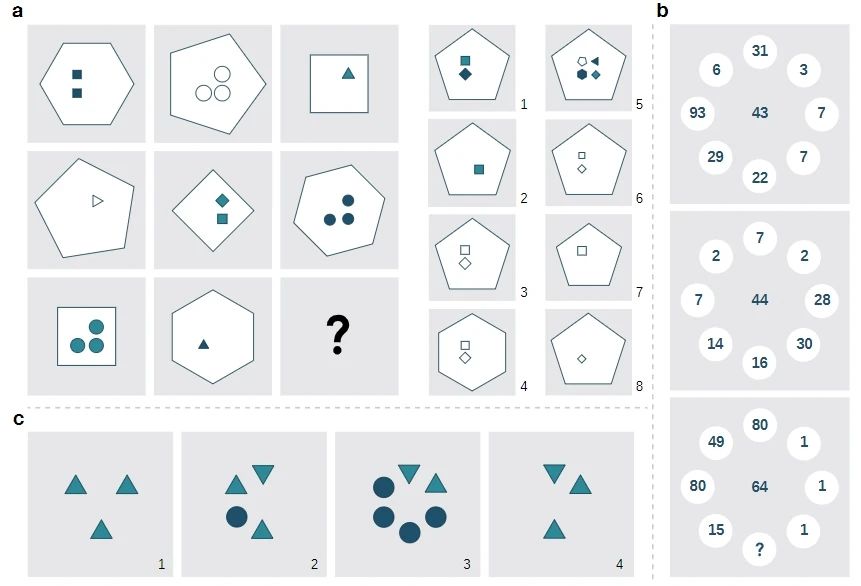
本研究模型在少样本概念归纳问题上成果显著,尤其在处理需要高度抽象思维的智力测试题目如瑞文测试(RPM)、数感(MNS)和异类甄别(O3)上表现突出。这些测试普遍用于评估人类智力,而该模型通过仅使用每个问题中的几个实例(而非依赖大量训练数据)成功解决了它们,突破了传统AI的局限。
瑞文测试(RPM)、数感(MNS)和异类甄别(O3)三个例子,分别是(a)瑞文测试,(b)数感,(c)异类甄别。
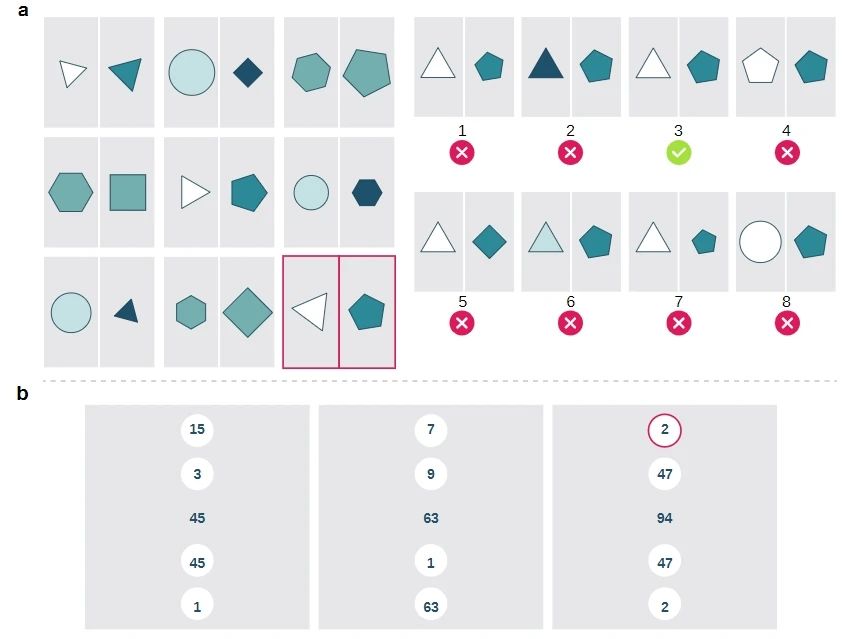
与其他模型和人类对比:
该模型(简称为ME模型)与多个现有的计算方法及人类参与者进行了比较。结果显示,ME模型不仅在多项任务上超越了传统的关系学习模型(如WReN, CoPINet, SCL)和流行的Transformer架构[2,3,7,8],还在测试中超过了人类参与者的表现。这表明ME模型能够以高效且独特的方式处理抽象推理任务,这些任务通常是人类智力的体现。
ME模型与其他模型和人类对比结果:可以看到ME模型相比其他模型,在各个难度范围和范化条件下均超过其他模型,也远远超过右侧的人类的统计结果。
模型的生成能力:
除了在已有任务上的表现外,ME模型还展示了其生成能力——在没有给定选项的情况下能从学习到的分布中生成答案。这一特性使得ME模型不仅可以作为判别模型使用,还可以作为生成模型使用。
效率与实用性:
最关键的是,这项研究强调了模型使用极少的数据(少样本)就能达到高效学习和推理的能力,这与传统需要大量数据和标签的深度学习模型形成鲜明对比。这种能力特别适合于数据稀缺的环境,或在需要迅速适应新任务和新环境的应用场景中,显著提高了AI的适用性和灵活性。
综上所述,这篇论文的结果不仅展示了其模型在抽象推理测试中的优越性能,也展示了AI在不依赖大数据的情况下,通过模拟人类的学习过程来达到甚至超越人类智力的潜力,即通过小数据完成大任务的能力,这种进步为人工智能的发展方向提供了新的视角,尤其是在促进机器理解和处理复杂抽象概念的能力方面。