
具身智能、机器人与增强现实的发展
都依赖机器对 3D 世界的理解与交互能力
要让智能体真正「走进物理世界」
需要两类互补的数据基础设施
一是可规模化生成、带完美标注的虚拟仿真数据
二是多样、真实、贴近人类日常分布的真实世界数据
2025年中关村论坛上
通研院发布三维场景重建与具身智能数据构建平台
“通通到我家”
该平台能“把现实世界搬进电脑”
可以根据任意图片或视频进行三维重建
快速构建高精度、可交互的三维虚拟空间
让智能体“通通”走进千家万户
近日,通研院在此基础上提出“SceneVerse++ ”
通过重建互联网视频并自动标注3D场景
把互联网上海量的视频「提炼」为
可训练的真实 3D 场景数据
结合 TongSim[1] 的虚拟仿真能力互为补充
共同构成「虚拟 + 真实」双轮驱动的
空间智能数据底座
该成果已被 CVPR 2026 接收,研究团队均为通研院具身机器人中心的研究员、工程师,通研院实习生以及通研院通计划联培博士生。
-
论文链接:https://arxiv.org/abs/2604.01907
-
项目主页:https://sv-pp.github.io/
-
数据集:
https://huggingface.co/datasets/bigai/SceneVersepp

图 1 SceneVerse++ 总览:从无标注互联网视频出发,经自动化数据引擎转化为可直接训练的 3D 场景理解数据。
论文概述:
从无标注视频到可训练的 3D 场景数据
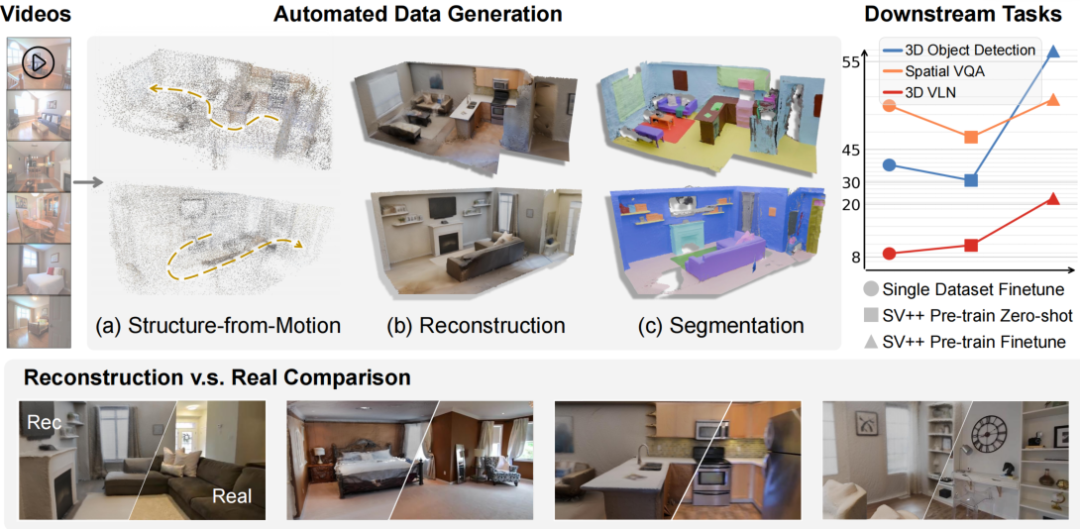
图 2 SceneVerse++ 总览:从无标注互联网视频出发,经自动化数据引擎转化为可用于 3D 检测、空间 VQA 与 VLN 等下游任务的训练数据。
在虚拟世界,通研院开源的 TongSim 已经为业界提供了高保真、可程序化控制的三维仿真平台:它支持任务级、物理级可控的场景生成与多模态交互,是训练与评估具身智能体的「数字孪生沙盘」。然而,仿真场景与真实世界仍然存在不可忽视的域差(domain gap)——真实房间的材质、光照、杂乱程度与布局多样性,是任何虚拟引擎都难以穷尽的。
论文《Lifting Unlabeled Internet-level Data for 3D Scene Understanding》提出了一整套面向 3D 场景理解的自动化数据引擎。整体流程由三个核心模块组成:
-
数据预处理与结构化建图:使用 TransNetV2 [2] 进行镜头切分与过滤、基于视差的关键帧抽取,完成密集像素匹配与全局光束法平差(BA),得到稳健的相机位姿与稀疏点云。
-
稠密重建与实例分割:以 SfM 稀疏点为先验,Prior Depth Anything [3] 预测度量深度,TSDF 融合得到水密网格,再逐帧 2D 分割,基于视图与空间一致性提升到 3D,自动生成语义描述与 ScanNet 类别标签。
-
下游任务数据派生:基于 3D 场景图自动生成 632K 条空间 VQA 样本(VSI-Bench [4] 格式);通过「路径预处理 + 动作编码 + CoT 指令生成」三阶段管线,产出 9,631 条 VLN 轨迹、21,567 条自然语言指令。
最终,团队从互联网视频中提炼出 6,687 个真实室内 3D 场景,在场景数量、场景面积、物体种类与物体数量四项指标上全面超越 ScanNet、ARKitScenes [5]、MultiScan [6],且天然包含多楼层、多房间的大范围复杂场景。
实验结果:三项任务全面提升
作者在三类代表性下游任务上系统评估了 SceneVerse++ 的价值:
-
3D 目标检测(SpatialLM [7]):SceneVerse++ 预训练 + ScanNet 微调取得 F1@0.25 = 58.6 / F1@0.5 = 45.4,较原合成数据预训练基线提升 +20.6 / +16.7 分,证明互联网真实视频比合成数据更贴合真实世界分布。
-
3D 空间视觉问答(Qwen-VL [8] on VSI-Bench):3B / 7B 模型平均提升 +14.9 / +9.8 分,证明互联网视频生成数据与仿真室内扫描数据在空间推理能力上的提升效果相当,在域外子集上表现甚至略优,说明互联网视频提供的先验对真实场景具有良好泛化性。
-
3D 视觉语言导航(R2R [10] 基准):SceneVerse++ 预训练 + 微调将成功率(SR)从 0.088 提升至 0.228(+159%),消融进一步验证了轨迹优化(TR)与指令增强(IE)两个子模块缺一不可。
结论:虚实互补,共筑 3D 空间智能「数据基建」
SceneVerse++ 证明:用精心设计的自动化数据引擎,互联网视频同样能成为高质量 3D 场景数据的来源。其价值不仅在于交付了当前最大规模的真实室内 3D 场景数据集,更在于为「用无标注数据规模化驱动 3D 空间智能」提供了可复现的路线图。
与 TongSim 的虚拟世界相呼应,SceneVerse++ 补齐了真实世界这一环——TongSim 提供可程序化、可对抗、可反事实的虚拟训练场;SceneVerse++ 提供规模化、长尾丰富的真实世界先验。两者联动,为具身智能体、3D 视觉-语言模型乃至下一代空间基础模型,构筑起「虚拟 + 真实」的完整数据底座。
在 3D 数据长期稀缺的背景下,「无标注互联网视频 × 高保真虚拟仿真」有望成为推动空间智能跨越式发展的关键路径。
/参考文献 /
[1] Sun, Zhe, et al. “TongSIM: A General Platform for Simulating Intelligent Machines.” arXiv preprint arXiv:2512.20206 (2025).
[2] Soucek, Tomás, and Jakub Lokoc. “Transnet v2: An effective deep network architecture for fast shot transition detection.” Proceedings of the 32nd ACM International Conference on Multimedia. 2024.
[3] Wang, Zehan, et al. “Depth anything with any prior.” arXiv preprint arXiv:2505.10565 (2025).
[4] Yang, Jihan, et al. “Thinking in space: How multimodal large language models see, remember, and recall spaces.” Proceedings of the Computer Vision and Pattern Recognition Conference. 2025.
[5] Baruch, Gilad, et al. “Arkitscenes: A diverse real-world dataset for 3d indoor scene understanding using mobile rgb-d data.” arXiv preprint arXiv:2111.08897 (2021).
[6] Mao, Yongsen, et al. “Multiscan: Scalable rgbd scanning for 3d environments with articulated objects.” Advances in neural information processing systems 35 (2022): 9058-9071.
[7] Mao, Yongsen, et al. “Spatiallm: Training large language models for structured indoor modeling.” arXiv preprint arXiv:2506.07491 (2025).
[8] Bai, Shuai, et al. “Qwen3-vl technical report.” arXiv preprint arXiv:2511.21631 (2025).
[9] Anderson, Peter, et al. “Vision-and-language navigation: Interpreting visually-grounded navigation instructions in real environments.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.


北京通用人工智能研究院