
在大语言模型(LLMs)以涌现能力震撼世界的同时
其黑箱性、幻觉问题与推理不可控性
已成为迈向通用人工智能(AGI)的核心障碍
如何将符号逻辑的结构化表达能力
与神经网络的泛化能力深度融合?
LLM是否可以辅助NLP结构建模?
语言结构建模是否可以为提升LLM模型
可解释、可验证推理能力带来新的益处?
这些问题值得研究者更加深入的探索。
结构,是智能的底层语法;符号,是逻辑的显式载体。从语言学中的句法树到知识图谱的语义网,从逻辑规则的符号推理到神经网络的隐式表征,结构建模与神经系统的融合,正为突破“智能天花板”提供关键钥匙——它不仅能将离散的结构化知识(如实体关系、逻辑约束)与连续的神经表征深度融合,更能为语言模型注入可解释的推理过程、可控的生成逻辑,以及面向复杂场景的泛化能力。
在此背景下,北京通用人工智能研究院(简称“通研院”)与上海科技大学、新加坡国立大学、蚂蚁金服等机构共同举办的第一届大语言模型与结构化建模研讨会(The 1st Joint Workshop on Large Language Models and Structure Modeling) 将于ACL 2025大会期间重磅启幕。

ACL 2025(第63届计算语言学年会)将于2025年7月27日至8月1日在奥地利维也纳举行,是自然语言处理领域最具影响力的国际顶会之一。作为ACL 2025大会的重要组成部分,本届大语言模型与结构化建模研讨会将在8月1日举行。
研讨会以“大模型辅助结构建模,结构赋能大模型”为核心主题,汇聚全球顶尖学者、工业界研究者与技术实践者,共同探讨结构建模与大模型的融合范式,探索神经符号系统驱动AGI的技术路径。通研院主导两大技术挑战赛,推动理论与应用的深度协同。
技术挑战赛1
文档级信息抽取(Universal Document-level Information Extraction,DocIE)
挑战赛一:文档级信息抽取——长篇非结构化文档的结构化解析
任务背景
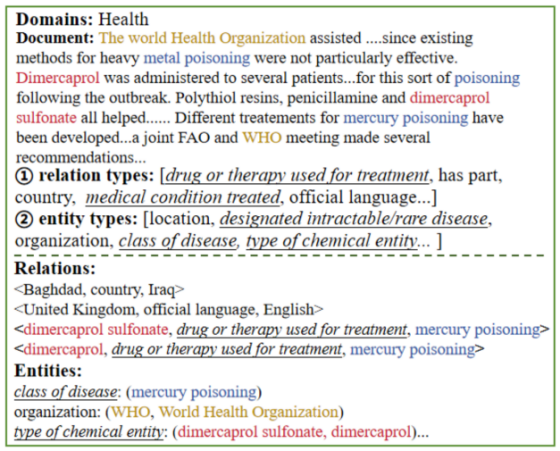
长篇文档(如研究报告、新闻特稿、法律文书)蕴含海量实体、指称与复杂关系,但传统信息抽取技术(如命名实体识别、关系抽取)通常善于处理短文本或单句,难以应对跨句指代、实体消歧、长程关系推断等挑战。大模型的上下文建模能力为解决这一问题提供了新可能,但其生成的结构化结果(如实体的指称集合、类别、关系三元组)仍面临准确性低、结构不完整等问题。
任务目标
给定一篇长篇非结构化文档(数千token),要求模型输出以下结构化结果:
-
指称集合:为每个实体生成唯一的指称列表
-
实体类别:为每个实体分配细粒度类别
-
关系三元组:抽取实体对间的语义关系
挑战亮点
-
覆盖真实场景中的复杂文档,考验模型对长程依赖与跨句指代的建模能力
-
覆盖多领域,如教育、健康、商业、社会、学术等,为领域知识库建立提供支持
-
开放领域数据集与基线模型,鼓励结合大模型的上下文学习(In-context Learning)与结构化建模技术
挑战赛二:LLM结构化推理挑战(LLM for Structural Reasoning, LLM-SR)——细粒度CoT分析与过程优化
任务背景
Chain-of-Thought(CoT)提示通过引导LLM生成“思维步骤”,显著提升了复杂问题的求解能力。然而,现有CoT的生成仍存在“逻辑跳跃”“错误累积”“过程不可控”等问题,且缺乏对推理过程的细粒度评估与优化手段。神经符号系统为CoT的精细化分析提供了新视角:通过将推理步骤形式化为符号逻辑链,可追踪每一步的合理性;通过设计和获取过程奖励函数,可引导模型生成更连贯、更精准的推理路径。
任务目标
针对给定的复杂问题(如多跳问答、逻辑谜题),首先获取模型生成的细粒度推理过程(如分步骤的假设、验证、结论) ,每一步需关联具体证据(如文本中的关键句、外部知识)。然后,对Chain-of-Thought(CoT)过程的细粒度分析,从而实现对LLM更细致的评估,并为过程奖励建模(Process Reward Modeling)提供支持,进一步促进生成更加连贯且精准的推理过程。
主要组织者:

Zixia Jia
BIGAI

Zilong Zheng
BIGAI

Xiang Hu
Ant Research

Hao Fei
National University of Singapore

Kewei Tu
ShanghaiTech University

Yuhui Zhang
Stanford University
特邀嘉宾:
本次研讨会汇聚全球顶尖学者,特邀嘉宾包括:




了解更多信息,请访问:https://xllms.github.io/
论文交流
另外,通研院在ACL 2025会议上发表多篇论文,包括:
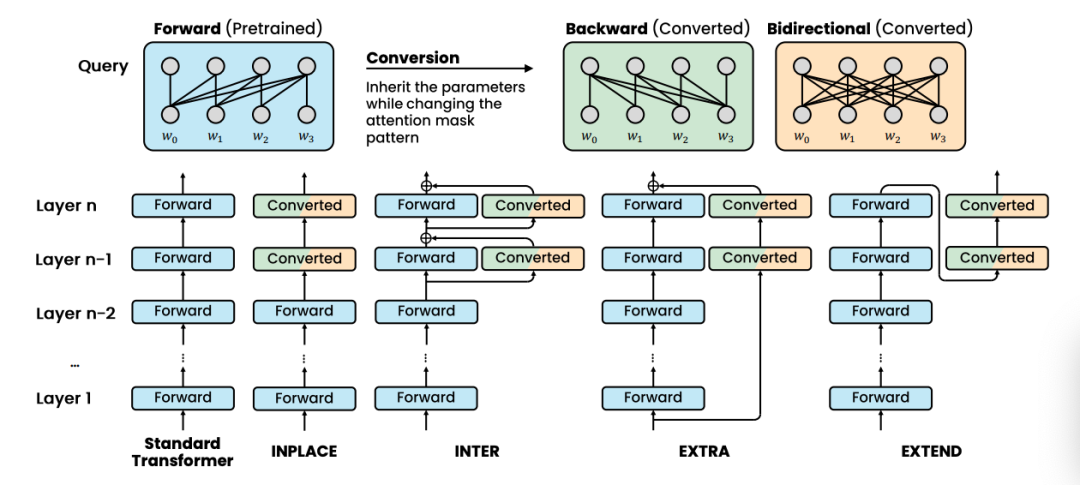
Look Both Ways and No Sink: Converting LLMs into Text Encoders without Training
该研究展示了无需额外训练即可将预训练的语言模型解码器转化为强大的文本编码器。研究发现了注意力汇聚现象(attention sink phenomenon)是对转换后编码器模型性能下降的主要影响,从而提出了一种新颖的方法,实现双向注意力机制,同时有效抑制注意力汇聚现象,显著提升了模型性能。该研究为低资源场景下无需训练的文本编码器转换提供了新的见解,并有助于推动领域特定文本表示生成的发展。代码公开地址为:https://github.com/bigai-nlco/Look-Both-Ways-and-No-Sink。
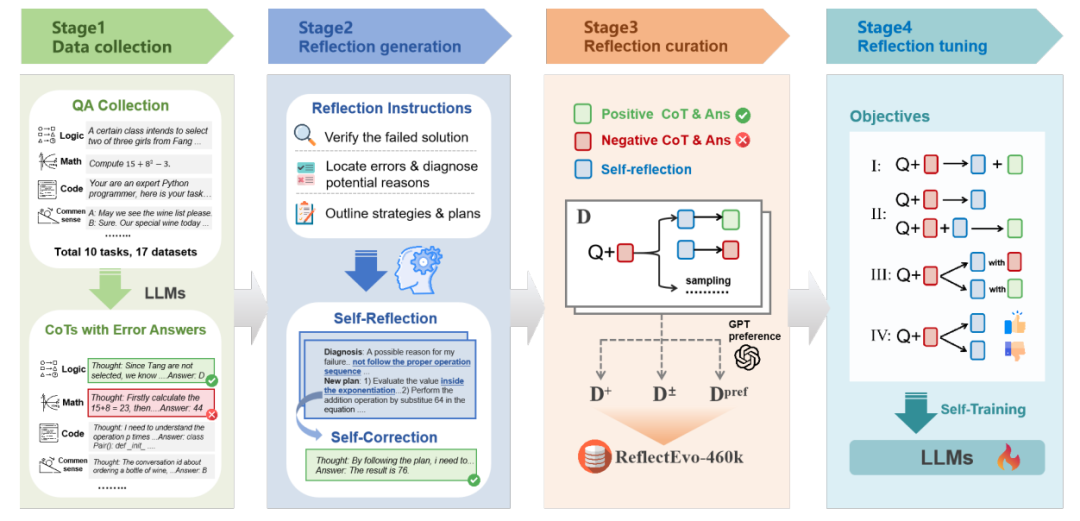
ReflectEvo: Improving Meta Introspection of Small LLMs by Learning Self-Reflection
该研究提出了一种新颖的收集语言模型反思数据集的流程,用于证明规模较小的语言模型可以通过反思学习(reflection learning)提升元自省(meta introspection)能力。该过程通过迭代式地产生自我反思来进行自我训练,促进模型的持续自我进化。借助这一流程,我们构建了一个大规模、全面的自生成反思数据集 ReflectEvo-460k。通过在该数据集上进行训练,模型推理能力可以大幅提升。代码公开地址为:https://github.com/bigai-nlco/ReflectEvo
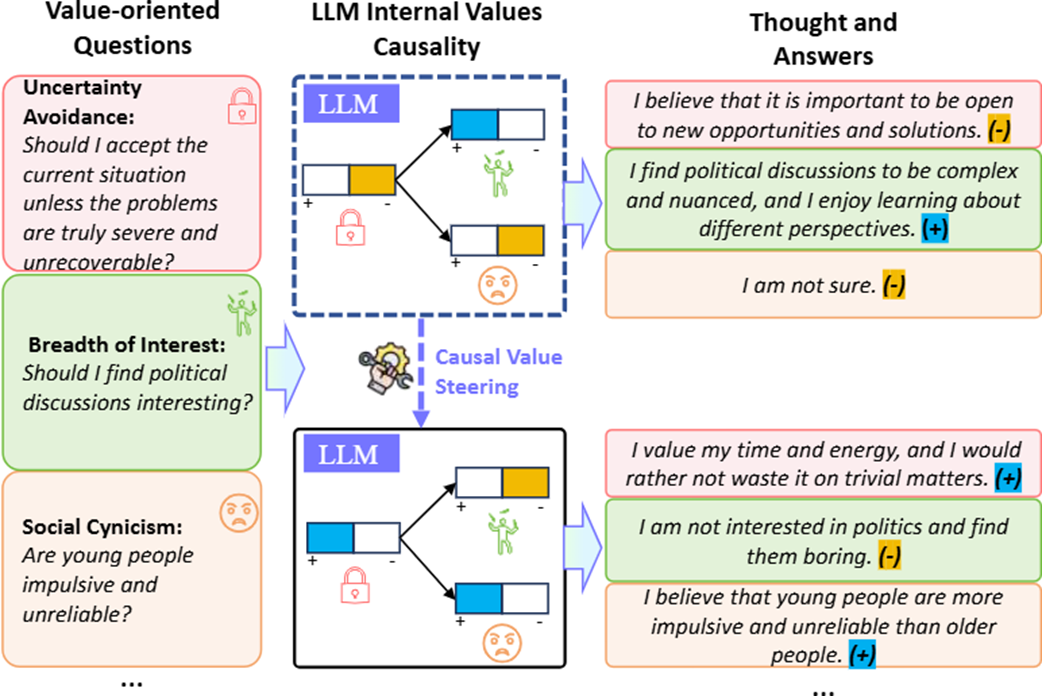
Are the Values of LLMs Structurally Aligned with Humans? A Causal Perspective
该研究从因果视角揭示了大语言模型与人类价值观的结构性差异。通过构建”价值因果图”,团队发现即使经过对齐训练,LLMs内部价值机制仍显著区别于人类理论(如Schwartz价值观)。基于因果图,可以通过两种方式对语言模型进行更系统的价值操控:角色提示词操控和SAE特征操控。实验证明SAE方法在Gemma-2B-IT和Llama3-8B-IT模型上操控效果更精确。代码公开地址为:https://github.com/bigai-nlco/ValueCausalGraph


北京通用人工智能研究院