
⼀个理想的具身智能体需可以仅凭交互
就学会⽤户定义的新任务
为此,智能体需要打破预设的通⽤识别规则
在与⽤户的持续交互中
识别其与用户在场景感知方面的差异
并进行在线更新
这种感知对⻬机制
是具身智能落地现实场景的重要挑战之⼀
北京通用人工智能研究院(简称“通研院”) 在ICRA2025发表了题为 《SYNERGAI: Perception Alignment for Human-Robot Collaboration》的论⽂ 提出了利⽤三维场景图和智能体 实现在线感知对⻬的SYNERGAI系统 通过融合三维场景图的结构化表征能力 与智能体的多模态推理优势 初步建立了人机协同的感知对齐范式 论⽂共同⼀作为通研院研究员 陈以新、张国熙、张耀威和徐宏明 共同通讯作者为李庆和⻩思远研究员 论⽂地址:https://synerg-ai.github.io
研究背景 当前,具身智能体可利⽤三维场景扫描与重建技术和多模态模型感知其所处的场景。但对物体的重建和识别尚不完美——它们能分辨“这是杯子”,却无法辨别这是你的咖啡杯还是酒杯。更重要的是,当智能体进入家庭,需要根据用户对物体的偏好动态地更新其感知。 比如,当用户严格区分咖啡杯和酒杯的使用场景时,智能体需能将此类个性化规则实时融入自己的认知系统。我们将上述智能体根据⼈类需求更新其场景感知的过程称之为感知对⻬。 感知对⻬⾯临两⽅⾯挑战:一方面,多数多模态模型将知识隐式存储于模型参数中,想要增加一条规则就需要微调大量参数,难以实现在线更新;另一方面,智能体需要在与用户交互的同时精准识别用户意图并提取需要更正的信息。
系统设计 对此,通研院提出的SYNERGAI系统可形象地理解为:装配了“结构化场景⼤脑“的智能体。其中“结构化场景⼤脑”以三维场景图(3D Scene Graph, 3DSG)[1] 的形式实现,就像一份动态更新的家居地图,整合了场景扫描数据和多种多模态模型给出的预测值。其中涉及的信息包括: 物品身份:名称、⼤⼩、坐标(位置)等; 属性特征:颜⾊、材质、属性等; 空间关系:物体间的⽀持、包含、临近等空间关系。
三维场景图将这些信息以图的形式进⾏表示:以图中节点表示物体,以节点属性表示物体属性,节点间的边表示物体间的空间关系。当需要更新场景知识时,只需要有针对性地修改对应的节点、节点属性或边即可。与基于⾼维向量的场景表征相⽐,这种结构化的表示形式可⽀持场景知识的在线更新,为感知对⻬创造了条件。
SYNERGAI的另⼀个重要组成部分是⼀个基于ReACT框架[2]的智能体,它可进⾏基于三维场景图的三维推理和感知对⻬。 如下图所示,该智能体在收到来⾃⽤户的请求后,会⾸先根据对⽤户意图的理解⽣成⼀个⼤致的规划,列出所涉及的⼯具(Tool),随后开始执⾏规划。
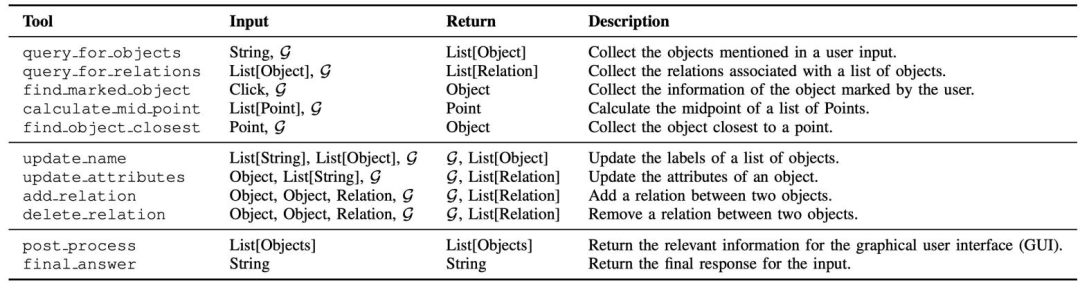
研究团队为这个智能体开发了5个信息检索⼯具和4个信息更新⼯具(如下表所示)。智能体可利⽤这些⼯具从三维场景图中检索物体和关系,并据此进⾏三维推理和问答。相较于将整个三维场景图嵌⼊提示词的⽅式,这种先检索再回答的⽅式更⾼效也更具可⾏性。同时,智能体在推测出⽤户希望更新其场景知识时,可利⽤这些⼯具更新场景图中的物体和关系。针对一些难以形容的物体,⽤户难以通过对话的形式描述想要查询或者更新的物体,研究人员为SYNERGAI开发了⼀个图形界⾯,允许⽤户通过⿏标点击的形式直接选择物体,并在⽂本对话中以“marked object”的形式指代该物体。
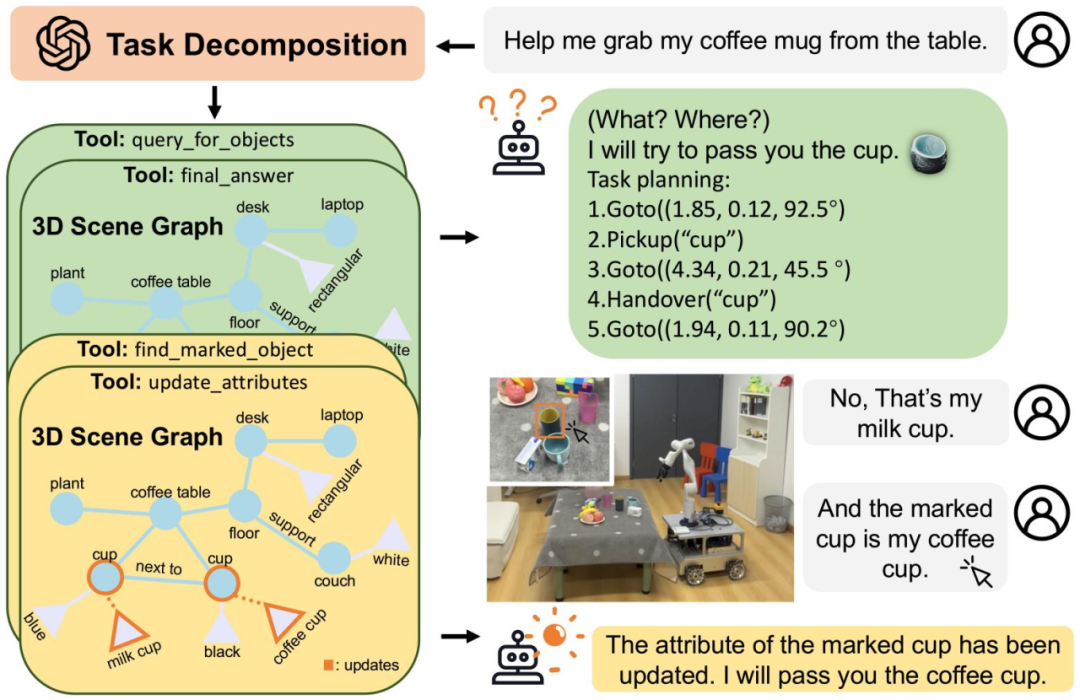

实验结果 研究团队从ScanNet数据集[3]中选取10个典型室内场景开展系统性验证。 ⾸先,在⼈⼯检查了这10个场景的三维场景图后,研究人员针对其中的感知错误设计了42个不同的感知对⻬任务,涵盖了物体标签、物体间的空间关系、物体属性等不同侧⾯,并按照这些任务所涉及的物体个数将其分为简单(Easy)和困难(Hard)两类。 下图给出了⼀个简单任务和⼀个复杂任务的例⼦。
随后,⼈类⽤户利⽤SYNERGAI完成这些感知对⻬任务,并分析任务完成率(SR)、智能体产⽣的回答中合理回答的⽐例(RR)、每个任务需要的⼈机交互次数(#Inter./Task)、每次交互触发的智能体的动作数(#Action/Inter.)和检索到的信息在三维场景图中的占⽐(QR,以token计数)等指标。 在下表中,SRHuman ⼀列表示经⼈机交互后系统的任务完成率,⽽SRInit和SRLLM则表示对⻬前的任务完成率和直接将待对⻬的信息附在问题后得到的任务完成率。
实验结果表明: 感知纠错有效性:基于SYNERGAI的感知对齐机制能有效修正智能体环境感知错误,任务完成率获得显著提升。相比直接提供正确答案,人机交互式感知对齐策略进一步有效提升任务成功率,其优势源于人类操作者可通过智能体反馈精准定位感知偏差源,并通过可视化界面实施针对性纠错。 用户满意度验证:在系统反馈的合理性评估中,61.90%的回答被用户判定为合理且可行,证明该感知对齐方案具备较高的实用性与人机协同效率。 数据效率优势:智能体平均仅需调用三维场景图中不足5%的元数据即可完成感知对齐,有力验证了”实体优先抽取-动态扩展”设计范式的可行性,显著降低了全场景数据处理的资源消耗。
结语 感知对齐问题作为具身智能体迈向大规模普适化应用的核心挑战之一亟待系统性突破。本研究提出的SYNERGAI系统不仅验证了结构化环境建模与动态认知推理的协同增效机制,更拓展了智能体在家庭服务机器人、工业协作系统等具身智能场景的应用边界,为构建可解释、可纠错的认知智能框架提供了重要实践参考。
/参考文献 /
[1] I. Armeni et al., “3D Scene Graph: A Structure for Unified Semantics, 3D Space, and Camera”, In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), 2019 [2] S. Yao et al., “ReAct: Synergizing Reasoning and Acting in Language Models”, In Proceedings of the Eleventh International Conference on Learning Representations (ICLR), 2023 [3] A. Dai et al., “ScanNet: Richly-annotated 3D Reconstructions of Indoor Scenes”, In Proceedings of the Thirtieth IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2017
北京通用人工智能研究院


